Unlock the secrets to enhanced productivity and seamless project management.
Introduction to Power Automate and Microsoft Planner
In today’s fast-paced business environment, mastering the art of productivity is not just an option, but a necessity. The dynamic duo of Microsoft Planner and Power Automate are our allies in the realm of project and task management. Imagine a world where our projects flow seamlessly, where every task aligns perfectly with your goals, and efficiency is not just a buzzword but a daily reality. This is all achievable with the integrations of Microsoft Planner and Power Automate in your corner.
Microsoft Planner, is our go-to task management tool, that allows us and our teams to effortlessly create, assign, and monitor tasks. It provides a central hub where tasks aren’t just written down but are actively managed and collaborated on. Its strength lies in its visual organization of tasks, with dashboard and progress indicators providing an bird’s-eye view of our project, making organization and prioritization a breeze. It is about managing the chaos of to-dos into an organized methodology of productivity, with each task moving smoothly from To Do to Done.
On the other side of this partnership we have Power Automate, the powerhouse of process automation. It bridges the gap between our various applications and services, automating the mundane so we can focus on what is important. Power Automate is our behind the scenes tool for productivity, connecting our favorite apps and automating workflows whether that’s collecting data, managing notifications, sending approvals, and so much more all without us lifting a finger, after the initial setup of course.
Together, these tools don’t just manage tasks; they redefine the way we approach project management. They promise a future where deadlines are met with ease, collaboration is effortless, and productivity peaks are the norm.
Ready to transform your workday and elevate your productivity? Let Microsoft Planner and Power Automate streamline your task management.
Here’s an overview of what is explored within this post. Start with an overview of Power Automate triggers and actions specific to Microsoft Planner or jump right to some example workflows.
- Introduction to Power Automate and Microsoft Planner
- Unveiling the Power of Planner Triggers in Power Automate
- Navigating Planner Actions in Power Automate
- Basic Workflows: Simplifying Task Management with Planner and Power Automate
- Advanced Workflows: Leveraging Planner with Excel and GitHub Integrations
- Unleashing New Dimensions in Project Management with Planner and Power Automate
Unveiling the Power of Planner Triggers in Power Automate
Exploring Planner triggers in Power Automate reveals a world of automation that streamlines task management and enhances productivity. Let’s dive into three key triggers and their functionalities.
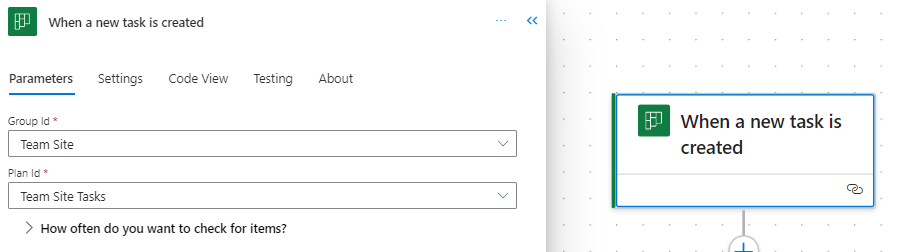
When a new task is created
This trigger jumps into action as soon as a new task is created in Planner. It requires the Group Id and Plan Id to target the specific Planner board. This trigger can set a series of automated actions into motion, such as sending notifications to relevant team members, logging the task in an Excel reporting workbook, or triggering parallel tasks in a related project.
When a task is assigned to me
This trigger personalizes your task management experience. It activates when a task in Planner is assigned to you. This trigger can automate personal notifications, update your calendar with the new tasks, or prepare necessary documents or templates associated with the task. Simply select this Planner trigger and it is all set, there is no additional information required by the trigger. It’s an excellent way to stay on top of personal responsibilities and manage your workload efficiently.

When a task is completed
The completion of a task in Planner can signal the start of various subsequent actions, hinging on the completion status of a task in a specified plan. The required inputs are the Group Id and the Plan Id to identify the target Planner board. This trigger is instrumental in automating post-task processes like updating project status reports, notifying team members or stakeholders of the task completion, or archiving task details for accountability and future reference.

By leveraging these Planner triggers in Power Automate, we can not only automate but also streamline our workflows. Each trigger offers a unique avenue to enhance productivity and ensures that our focus remains on strategic and high-value tasks.
Navigating Planner Actions in Power Automate
Navigating the complexities of project management requires tools that offer both flexibility and control. The integration of Microsoft Planner actions within Power Automate provides a robust solution for managing tasks efficiently. By leveraging Planner actions in Power Automate, we can automate and refine our task management processes. Let’s dive into some of the different Planner actions.
Adding and Removing assignees
Task assignment is a critical aspect of project management. These actions in Power Automate facilitate flexible and dynamic assignment and reassignment of team members to tasks in Planner, adapting to the ever-changing project landscape.
Add assignees to a task
This action allows us to assign team members to specific tasks, with inputs including the task ID and the user ID(s) of the assignee(s). It’s particularly useful for quickly adapting to changes in project scope or team availability, ensuring that tasks are always in the right hands.

Remove assignees from a task
Inputs for this action are the task ID and the user ID(s) of the assignee(s) to be removed. It’s essential for reorganizing task assignments when priorities shift or when team members need to be reallocated to different tasks, maintaining optimal efficiency.
Creating and Deleting tasks
The lifecycle of a task within any project involves its creation and eventual completion or removal. These actions in Power Automate streamline these essential stages, ensuring seamless task management within Planner.
Create a task
Every project begins with a single step, or in the case of our Planner board, a single task. To create a task we must provide the essentials, including Group Id, Plan Id, and Title. This action is invaluable for initiating tasks in response to various Power Automate triggers, such as email requests or meeting outcomes, ensuring timely task setup.

When using the new Power Automate designer (pictured above), be sure to provide all optional details of the task by exploring the Advanced parameters dropdown. Under the advanced parameters we will find task details to set in order to create a task specific to what our project requires. We can set the newly created task’s Bucket Id, Start Date Time, Due Date Time, Assigned User Id, as well as applying any tags needed to create a detailed and well defined task. When using the classic designer we will see all these options listed within the action block.
Delete a task
Keeping our Planner task list updated and relevant is equally important to successful project lifecycle management. Removing completed, outdated, or irrelevant tasks can help us maintain clarity and focus on the overall project plan. This action just requires us to provide the Task Id of the task we want deleted from our Planner board.
Getting and Updating tasks
Accessing and updating task information are key aspects of maintaining project momentum. These actions provide the means to efficiently manage task within Planner.
Get a task
Understanding each task’s status is crucial for effective management, and the Get a task action offers a window into the life of any task in our Planner board. By providing the Task Id, this action fetches the task returning information about the specific task. It is vital for our workflows that require current information about a task’s status, priority, assignees, or other details before proceeding to subsequent steps. This insight is invaluable for keeping a pulse on our projects progress.

Update a task
This action, requires the Task Id and the task properties to be updated, allowing for real-time modifications of task properties. It is key for adapting tasks to new deadlines, changing assignees, or updating a task’s progress. Using this action we can ensure that our Planner board always reflects the most current state of our tasks providing a current overview of the overall project status.

Getting and Updating task details
Detailed task management is often necessary for complex projects. These actions cater to this need by providing and updating in-depth information about tasks in Planner.
Get task details
Each task in a project has its own story, filled with specific details and nuances. This action offers a comprehensive view of a task, including its description, checklist items, and more. It is an essential action for workflows that require a deep understanding of task specifics for reporting, analysis, or decision making.

Update task details
With inputs for detailed aspects of our tasks, such as its descriptions and checklist items, this action allows for precise and thorough updates to our task information. It is particularly useful for keeping tasks fully aligned with project developments and team discussions.

List buckets
Effective task categorization is vital for clear project visualization and management. The List buckets action in Power Automate is designed to provide a comprehensive overview of task categories or buckets within our Planner board. We provide this action the Group Id and Plan Id and it returns a list of all the buckets within the specified plan, including details like bucket Id, name, and an order hint.
This information can aid in our subsequent actions, such as creating a new task within a specific bucket on our Planner board.

List Tasks
Keeping a tab on all tasks within a project is essential for effective project tracking, reporting, and management. The List tasks action in Power Automate offers a detailed view of tasks within a specific planner board.
We need to provide this action the Group Id and Plan Id, and it provides a detailed list of all tasks. The details provided for each task include the title, start date, due date, status, priority, how many active checklist items the task has, categories applied to the task, who created the task, and who the task is assigned to. This functionality is invaluable for teams to gain insights into task distribution, progress, and pending actions, ensuring that no task is overlooked and that project milestones are met.

Basic Workflows: Simplifying Task Management with Planner and Power Automate
Before diving into some more advanced examples and integrations, it is essential to understand how Planner and Power Automate can simplify everyday task management through some basic workflows. These workflows will provide a glimpse into the potential of combining these two powerful tools.
Weekly Summary of Completed Tasks
This workflow automates the process of summarizing completed tasks in Planner, sending a weekly email to project managers so they can keep their finger on the pulse of project progress.
The flow has a reoccurrence trigger which is set to run the workflow on a weekly basis. The workflow then starts by gathering all the tasks from the planner board using the List tasks action. This action provides two helpful task properties that we can use to pinpoint the task that have been completed in the last week.
The first is percentComplete, we add a filter data operation action to our workflow and filter to only tasks that have a percentComplete equal to 100 (i.e. are marked completed). We set the From input to the value output of the List task action and define our Filter Query.

The second property we can use from List tasks is the completedDateTime, we can use this to further filter our completed task to just those completed within the last week. Here we use the body of our Filter array: Completed tasks action and use an expression to calculated the difference between when the task was completed and when the flow is ran, in days.

The expression used in the filter query is:
int(split(dateDifference(startOfDay(getPastTime(1, 'Week')), item()?['completedDateTime']), '.')[0])
This expression starts by getting the start of the day 1 week ago using getPastTime and startOfDay. Then we calculate the difference using dateDifference. The date difference function will return a string value in the form of 7.00:00:00.0000000, representing Days.Hours:Minutes:Seconds. For our purposes we are only interested in the number of days, specifically whether the value is positive or negative, that is was it completed before or after the date 1 week ago. To extract just the days as an integer we first use split to split the string based on periods, and then we use the first item in the resulting array ([0]), and pass this to the int function, to get a final integer value.
We then use the Create HTML table action to create a summary table of the Planner tasks that were completed in the past week.

Then we can send out an email to those that require the weekly summary of completed tasks, using the output of the Create HTML table: Create summary table action.

Here is an overview of the entire Power Automate workflow that automates our process of summarizing our Planner tasks that have been completed in the past week.

This automated summary is invaluable for keeping track of progress and upcoming responsibilities, ensuring that our team is always aligned and informed about the week’s achievements and ready to plan for what is next.
Post a Teams message for Completed High Priority Tasks
This workflow is tailored to enhance team awareness and acknowledgement of completed high-priority tasks. It automatically sends a Teams notification when a high-priority task in Planner is marked as completed.
The workflow triggers when a Planner task on the specified board is marked complete. The workflow then examines the priority property of the task to determine if a notification should be sent. For the workflow a high-priority task is categorized as a task marked as Important or Urgent in Planner.

The workflow uses a condition flow control to evaluate each task’s priority property. An important note here is that, although in Planner the priorities are shown as Low, Medium, Important, and Urgent, the property values associated with these values are stored in the task property as 9, 5, 3, 1, respectively. So the condition used evaluates to true if the priority value is less than or equal to 3, that is the task is Important or Urgent.
When the condition is true, the workflow gathers more details about the task and then sends a notification to keep the team informed about these critical tasks.

Let’s break down the three actions used to compose and send the Teams notification. First, we use the List buckets action to provide a list of all the buckets contained within our Planner board. We need this to get the user friendly bucket name, because the task item only provides us the bucket id.
Then we can use use the Filter data operation to filter the list of all the buckets to the specific bucket the complete task resides in.

Here, value is the output of our List bucket action, id is the current bucket list item, and bucketId is the id of the current task item of the For each: Completed task loop. We can then use the dynamic content from the output of this action to provide a bit more detail to our Teams notification.
Now we can piece together helpful information and notify our team when high-priority tasks are completed using the Teams Post a message in a chat or channel action, shown above. Providing our team details like the task name, the bucket name, and a link to the Planner board.
These basic yet impactful workflows illustrate the seamless integration of Planner with Power Automate, setting the stage for more advanced and interconnected workflows. They highlight how simple automations can significantly enhance productivity and team communication.
Advanced Workflows: Leveraging Planner with Excel and GitHub Integrations
The integration of Microsoft Planner with other services through Power Automate unlocks new dimensions in project management, offering innovative ways to manage tasks and enhance collaboration.
Excel Integration for Reporting Planner Tasks
A standout application of this integration is the reporting of Planner tasks in Excel. By establishing a flow in Power Automate, task updates from Planner can be seamlessly merged to an Excel workbook. This setup is invaluable for generating detailed reports, tracking project progress, and providing more in-depth insights.
For an in-depth walkthrough of a workflow, leveraging this integration check out this post that covers the specifics of setting up and utilizing this integration.

Transforming Project Tracking: How to Merge Planner with Excel Using Power Automate
Explore the Detailed Workflow for Seamless Task Management and Enhanced Reporting Capabilities.
GitHub Integration for Automated Task Creation
Combining Planner with GitHub through Power Automate creates a streamlined process for managing software development tasks. A key workflow in this integration is the generation of Planner tasks in response to new GitHub issues assigned to you. When an issue is reported in GitHub, a corresponding task is automatically created in Planner, complete with essential details from the GitHub issue. This integration ensures prompt attention to issues and their incorporation into the broader project management plan.
Check back, for a follow up post focus specifically on providing a detailed guide on implementing this workflow.
These advanced workflows exemplify the power and flexibility of integrating Planner with other services. By automating interactions across different platforms, teams can achieve greater efficiency and synergy in their project management practices.
Unleashing New Dimensions in Project Management with Planner and Power Automate
Finishing our exploration of Microsoft Planner and Power Automate, it’s evident that these tools are more than mere facilitators of task management and workflow automation. They embody a transformative approach to project management, blending efficiency, collaboration, and innovation in a unique and powerful way.
The synergy between Planner and Power Automate opens up a realm of possibilities, enabling teams and individuals to streamline their workflows, integrate with a variety of services, and automate processes in ways that were previously unimaginable. From basic task management to complex, cross-platform integrations with services like Excel and GitHub, these tools offer a comprehensive solution to the challenges of modern project management.
The journey through the functionalities of Planner and Power Automate is a testament to the ever-evolving landscape of digital tools and their impact on our work lives. As these tools continue to evolve, they offer fresh opportunities for enhancing productivity, fostering team collaboration, and driving innovative project management strategies.
Experiment with these tools and explore the myriad of features they have to offer, and discover new ways to optimize your workflows. The combination of Planner and Power Automate isn’t just a method for managing tasks; it’s a pathway to redefining project management in the digital age, empowering teams to achieve greater success and efficiency.
Thank you for reading! Stay curious, and until next time, happy learning.

And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment, explore, and challenge yourself with real-world scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.