Discover how to Reshape, Manipulate, and Transform your data into dynamic insights.
Exploring DAX: Table Manipulation Functions
Dive into the world of DAX and discover its critical role in transforming raw data into insightful information. With DAX in Power BI, we are equipped with a powerful tool providing advanced data manipulation and analysis features.
Despite its advanced capabilities, DAX remains approachable, particularly its table manipulations functions. These functions are the building blocks of reshaping, merging, and refining data tables, paving the way for insightful analysis and reporting.
Let’s explore DAX table manipulations functions and unlock their potential to enhance our data analysis. Get ready to dive deep into each function to first understand it and then explore practical examples and applications.
For those of you eager to start experimenting there is a Power BI report pre-loaded with the same data used in this post ready for you. So don’t just read, follow along and get hands-on with DAX in Power BI. Get a copy of the sample data file here:

GitHub – Power BI DAX Function Series: Mastering Data Analysis
This dynamic repository is the perfect place to enhance your learning journey.
Here is what the post will cover:
- ADDCOLUMNS: Adding More Insights to Your Data
- Joining Tables with DAX: CROSSJOIN, NATURALINNERJOIN & NATURALLEFTOUTERJOIN
- GROUPBY: The Art of Segmentation
- SUMMARIZE & SUMMARIZECOLUMNS: Summary Magic
- ROLLUP: Climbing the Aggregation Ladder
- SELECTCOLUMNS: Handpicking Your Data
- UNION, INTERSECT, EXCEPT: Set Operations in DAX
- DISTINCT: Identifying Unique Values
- TREATAS: Bridging Data Tables
ADDCOLUMNS: Adding More Insights to Your Data
When it comes to enhancing our data tables in Power BI, ADDCOLUMNS is one of our go-to tools. This expression helps us add new columns to an existing table, which can be incredibly handy for including calculated fields or additional information that was not in the original dataset.
The syntax for ADDCOLUMNS is straightforward.
ADDCOLUMNS(table, name, expression[, name, expression]...)
Here, <table> is an existing table or any DAX expression that returns a table of data, <name> is the name given to the column and needs be enclosed in double quotes, and finally <expression> is any DAX expression that returns a scalar value that is evaluated for each row of <table>.
Let’s take a look how we can create a comprehensive date table using ADDCOLUMNS. We will start with the basics by creating the table using CALENDARAUTO() and then enrich this table by adding several time-related columns.
DateTable =
ADDCOLUMNS (
CALENDARAUTO(),
"Year", YEAR([Date]),
"YearQuarter", FORMAT([Date], "YYYY \QTR-q"),
"YearQuarterSort", YEAR([Date]) & QUARTER([Date]),
"Quarter", QUARTER([Date]),
"MonthName", FORMAT([Date], "MMMM"),
"MonthShort", FORMAT([Date], "mmm"),
"MonthNumber", MONTH([Date]),
"MonthYear", FORMAT([Date], "mmm YYYY"),
"MonthYearSort", FORMAT([Date], "YYYYMM"),
"Day", DAY([Date]),
"Weekday", WEEKDAY([Date]),
"WeekdayName", FORMAT([Date], "DDDD"),
"DateKey", FORMAT([Date], "YYYYMMDD")
)
In this example, we transform a simple date table into a multifaceted one. Each additional column provides a different perspective of the date, from the year and quarter to the month name and day of the week. This enriched table becomes a versatile tool for time-based analysis and reporting in Power BI.

With ADDCOLUMNS, our data tables go beyond just storing data, they become dynamic tools that actively contribute to our data analysis, making our reports richer and more informative.
Joining Tables with DAX: CROSSJOIN, NATURALINNERJOIN & NATURALLEFTOUTERJOIN
In Power BI, combining different datasets effectively can unlock deeper insights. DAX offers powerful functions like CROSSJOIN, NATURALINNERJOIN, and NATURALLEFTOUTERJOIN to merge tables in various ways, each serving a unique purpose in data modeling.
CROSSJOIN: Creating Cartesian Products
CROSSJOIN is our go-to function when we need to combine every row of one table with every row of another table, creating what is known as a Cartesian product. The syntax is simple.
CROSSJOIN(table, table[, table]…)
Here<table> is any DAX expression that returns a table of data. The columns names from the <table> arguments must all be different in all tables. When we use CROSSJOIN the number of rows in the resulting table will be equal to the product of the number of rows from all <table> arguments, and the total number of columns is the sum of all the number of columns in all tables.
We can use CROSSJOIN to create a new table containing every possible combination of products and regions within our dataset.
ProductsRegionsCross =
CROSSJOIN(Products, Regions)
This formula will create a new table where each product is paired with every region, providing a comprehensive view for various analysis task such as product-region performance assessments.

NATURALINNERJOIN & NATURALLEFTOUTERJOIN: Simplifying Joins
When it comes to joining tables based on common columns, NATURALINNERJOIN and NATURALLEFTOUTERJOIN can be helpful. These functions match and merge tables based on column with the same names and data types.
NATURALINNERJOIN creates a new table containing rows that have matching values in both tables, this function performs an inner join of the tables. Here is the syntax.
NATURALINNERJOIN(left_table, right_table)
The <left_table> argument is a table expression defining the table of the left side of the join, and the <right_table> argument defines the table on the right side of the join. The resulting table will include only the rows where the values in the common columns are present in both tables. This table will have the common columns from the left table and other columns from both tables.
For instance, to see products data and sales data for only products that have sales we could create the following table.

NATURALLEFTOUTJOIN, on the other hand, includes all the rows from the first (left) table and the matched rows from the second (right) table. Unmatched rows in the first table will have null values in columns of the second table. This is useful for scenarios where we need to maintain all records from one table while enriching it with data from another. Its syntax is the same as NATURALINNERJOIN.
NATURALLEFTOUTERJOIN(left_table, right_table)
The resulting table will include only rows from the <right_table> where the values in the common columns specified are also present in the <left_table>.
Let’s explore this and how it differs from NATURALINNERJOIN by creating the same table as above but this time using NATURALLEFTOUTERJOIN.

Here we can see the inclusion of our TV line of products, which have no sales. NATURALLEFTOUTERJOIN provides a list of all products, along with the sales data where it is available for each product. While the previous example shows that NATURALINNERJOIN provides only products and sales where the ProductID is matched between these two tables.
Each of these functions serves a distinct purpose: CROSSJOIN for comprehensive combination analysis, NATURALINNERJOIN for intersecting data, and NATURALLEFTOUTERJOIN for extending data with optional matching from another table. Understanding when to use each will significantly enhance our data modeling in Power BI.
GROUPBY: The Art of Segmentation
Segmenting data is a cornerstone of data analysis, and in Power BI, the DAX GROUPBY function is a powerful ally for this task. GROUPBY allows you to group a table by one or more columns and performs calculations on each group. It helps us organize our data into manageable clusters, then glean insights from each cluster. The syntax for GROUPBY is as follows.
GROUPBY (table [, groupBy_columnName[, groupBy_columnName[, …]]] [, name, expression [, name, expression [, …]]])
Let’s break this down. The <table> argument is any DAX expression that returns a table of data. The <groupBy_columnName> argument is the name of an existing column in <table> (or a related table) by which the data is to be grouped and cannot be an expression. The <name> argument is the name given to a new column that is being added to the list returned by GROUPBY enclosed in double quotes. Lastly, <expression> is the expression to be evaluated for each group and must be a supported aggregation iterator function.
For details on aggregation iterator functions visit this in-depth post.

Dive Into DAX: Data Aggregation Made Easy
A guide to transforming data into meaningful metrics: Explore essential aggregation functions.
Let’s get into some details and examples.
The general use of GROUPBY is to create a table with a new column(s) which contain aggregated results. When using GROUPBY for grouping and aggregation we must be familiar with the related CURRENTGROUP function. The CURRENTGROUP function returns the set of rows from the table argument of the GROUPBY function that belongs to the current row of the GROUPBY results, and the function can only be used within the GROUPBY expression. This function has not argument and is only supported as the first argument to a supported aggregation function, for a list of supported functions see the reference document below.

CURRENTGROUP Function (DAX) | Microsoft Learn
Learn more about: CURRENTGROUP
We will start with a basic use of GROUPBY to analyze our sales by product. We can try to create a new table using the following expression.
Sales by Product =
GROUPBY(
Sales,
Products[Product],
"Total Sales", SUM(Sales[Amount])
"Average Sales", AVERAGE(Sales[Amount)
)
However, we will see this returns an error stating:
Function 'GROUPBY' scalar expression have to be Aggregation functions over CurrentGroup(). The expression of each Aggregation has to be either a constant or directly reference the column in CurrentGroup().

We can correct this and get our expected results but updating our expression to:
Sales by Product =
GROUPBY(
Sales,
Products[Product],
"Total Sales", SUMX(CURRENTGROUP(), Sales[Amount]),
"Average Sales", AVERAGEX(CURRENTGROUP(), Sales[Amount])
)

Although we can use GROUPBY to create the above summary table, for efficient aggregations over physical tables in our data model such as our Sales table we should conder using the functions SUMMARIZECOLUMNS or SUMMARIZE. We will explore these functions later in this post. The true power of GROUPBY is to perform aggregations over intermediate results from DAX table expressions.
We will leverage this use case by creating a new measure that calculates the total sales amount for each product category, but only for the categories where the average sales amount per transaction exceeds a threshold. Here is how we can use GROUPBY and a virtual table to define the Total Sales by High Performing Categories measure.
Total Sales by High Performing Categories =
VAR ThresholdAverage = 3500
VAR IntermediateTable = GROUPBY(
Sales,
Products[Product],
"Total Sales", SUMX(CURRENTGROUP(), Sales[Amount]),
"Average Sales", AVERAGEX(CURRENTGROUP(), Sales[Amount])
)
VAR FilteredTable = FILTER(
IntermediateTable,
[Average Sales] > ThresholdAverage
)
RETURN
SUMX(FilteredTable, [Total Sales])
In this measure we first define the threshold average as $3,500. Then using GROUPBY we create an intermediate table that groups our sales by product and calculates the total sales and average for each product, this is the same expression we used in the above example. We then create another table by filtering the intermediate table to include only the product groups where the average sales exceed the defined threshold. Then we use SUMX to sum up the total sales from the filtered tabled.

We can see the measure returns a total sales value of $267,000 which from the previous example we can see is the sum of our total sales for our Laptop and Tablet product categories, leaving out the Smartphone category which has an average of $3,379 and is below the threshold. This measure effectively uses GROUPBY to segment and analyze our data in a sophisticated manner, tailoring the calculation to specific business requirements.
Using GROUPBY in measures provides immense flexibility in Power BI, enabling us to perform complex aggregations and calculations that are directly reflected in our report visuals.
SUMMARIZE & SUMMARIZECOLUMNS: Summary Magic
In Power BI, creating summary tables is a common requirement, and DAX offers us two powerful functions for this purpose: SUMMARIZE and SUMMARIZECOLUMNS. These functions are designed to simplify the process of aggregating and summarizing data, making it easier to create our reports and dashboards.
SUMMARIZE: The Classic Aggregator
SUMMARIZE allows us to create a summary table by specifying the columns we want to group by and the aggregations we want to perform. It is particularly useful for creating customized groupings and calculations. Here is its syntax.
SUMMARIZE (table, groupBy_columnName[, groupBy_columnName]…[, name, expression]…)
Here, <table> can be any DAX expression that returns a table of data, <groupBy_columnName> is optional and is the name of an existing column used to create summary groups, <name> is the name given to a summarized column enclosed in double quotes, and <expression> is any DAX expression that returns a single scalar value.
Let’s see how we can more effectively create our Sales by Product summary table. We will create a Sales by Product SUMMARIZE table using the following:
Sales by Product SUMMARIZE =
SUMMARIZE(
Sales,
Products[Product],
"Total Sales", SUM(Sales[Amount]),
"Average Sales", AVERAGE(Sales[Amount])
)
A key difference to note is the use of SUM and AVERAGE compared to the use of SUMX and AVERAGEX that were required when we used GROUPBY. Unlike GROUPBY the SUMMARIZE function has an implied CALCULATE providing the required context to aggregate our values.

SUMMARIZECOLUMNS: Enhanced Efficiency and Flexibility
SUMMARIZECOLUMNS offers enhanced efficiency and flexibility, especially in handling complex filter contexts. It may be preferred over SUMMARIZE for its performance benefits and ease of use with measures. The syntax is:
SUMMARIZECOLUMNS(groupBy_columnName[, groupBy_columnName]…, [filter_table]…[, name, expression]…)
The <groupBy_columnName> argument is a column reference to a table within our data model, the <filterTable> is a table expression which is added to the filter context of all columns specified by <groupBy_columnName>, <name> specifies the column name, and the <expression> is any DAX expression that returns a single value.
We are interested in calculating the total and average sales by product and region, but only for the previous year. This is a common scenario in business analysis, where understanding historical performance is key. We can use SUMMARIZECOLUMNS to help us achieve this.
We will create a new Last Year Sales by Product and Region table using the following:
Last Year Sales by Product and Region =
SUMMARIZECOLUMNS(
Regions[Region],
Products[Product],
Filter(Sales, Year(Sales[SalesDate]) = Year(TODAY())-1),
"Total Sales", SUM(Sales[Amount]),
"Average Sales", AVERAGE(Sales[Amount])
)
Here we begin with defining the dimension for group with Regions[Region] and Products[Product], this means our resulting summary will include these two levels of data granularity. The FILTER function is applied to the Sales table to include only sales records from the last year. This is achieved by comparing the year of the SalesDate to the previous year (YEAR(TODAY()) - 1). We then define two new columns in our summary: Total Sales, which sums up the amount for each product-region combination, and Average Sales, which calculates the average sales amount.

This example highlights SUMMARIZECOLUMNS and its strength in handling complex data relationships and filters. By seamlessly integrating time-based filtering and multi-dimensional grouping, it enables the creation of insightful, context-rich summary tables, pivotal for time-sensitive business analysis.
In summary, while SUMMARIZE is great for basic aggregation tasks, SUMMARIZECOLUMNS is the go-to function for more complex scenarios, offing better performance and handling of filter context in Power BI.
ROLLUP: Climbing the Aggregation Ladder
The ROLLUP function in DAX is a robust tool in Power BI for creating layered aggregations, especially useful in multi-level data analysis. It facilitates the generation of subtotals and grand totals within a single query, offering a detailed yet consolidated view of your data. ROLLUP modifies the behavior of the SUMMARIZE function by adding rollup rows to the results on columns defined by the <groupBy_columnName> argument.
Understanding the syntax and functionality of ROLLUP is key to leveraging its full potential. The basic syntax of ROLLUP is as follows:
ROLLUP (groupBy_columnName [, groupBy_columnName [, … ]])
The <groupBy_columnName> argument is a name of an existing column or ROLLUPGROUP function to be used to create summary groups.
To better understand our resulting summary table when using ROLLUP we can incorporate another helpful function: ISSUBTOTAL. We can use ISSUBTOTAL to create another column within our SUMMARIZE expression that returns true if the row contains a subtotal value for the column passed to ISSUBTOTAL as an argument.
Let’s explore an example. Suppose we want to analyze sales data and see subtotals at different levels: by region, then by product within each region, and finally a grand total across all regions and products. Here is how ROLLUP and ISSUBTOTAL can help.
Sales by Region and Production Rollup =
SUMMARIZE(
Sales,
Regions[Region],
ROLLUP(Products[Product]),
"Total Sales", SUM(Sales[Amount]),
"Product SubTotal", ISSUBTOTAL(Products[Product])
)
This example uses SUMMARIZE and groups our Sales data by Region. Then using ROLLUP it generates subtotals first at the product level within each region, followed by region-level subtotals. Total Sales calculates the sum of sales amounts for each group. Product SubTotals, through ISSUBTOTAL indicates whether a row is a subtotal for a product, enhancing the analysis by clearly marking these subtotal rows.

This approach, using ROLLUP with SUMMARIZE is highly effective for multi-layered data analysis. It allows for an intricate breakdown of data, showcasing how individual segments (in the example, products within regions) cumulatively contribute to broader totals. Such a perspective is critical for in-depth data analysis and informed decision-making.
SELECTCOLUMNS: Handpicking Your Data
In Power BI, tailoring our dataset to include just the right columns is often essential for efficient and focused analysis. This is where the SELECTCOLUMNS function in DAX becomes invaluable. SELECTCOLUMNS allows us to create a new table by selecting specific columns from an existing table. The syntax for SELECTCOLUMNS is straightforward:
SELECTCOLUMNS(table, [name], expression, name], …)
The arguments of this function are <table> which is any DAX expression that returns a table, <name> is the name given to the column, and <expression> is any expression that returns a scalar value.
Let’s use SELECTCOLUMNS to create a simplified table from our dataset, focusing on product sales and the corresponding sales date.
Simplified Product Sales =
SELECTCOLUMNS(
Sales,
"Product Name", RELATED(Products[Product]),
"Sales Amount", Sales[Amount],
"Date of Sale", Sales[SalesDate]
)

UNION, INTERSECT, EXCEPT: Set Operations in DAX
Set operations in DAX including UNION, INTERSECT, and EXCEPT are fundamental in Power BI for efficiently managing and manipulating data sets. Each operation serves a unique purpose in data analysis, allowing for combining, intersecting, and differentiating data sets.
UNION: Merging Data Sets
UNION is used to combine two or more tables by appending rows from one table to another. The tables must have the same number of columns, and corresponding columns must have compatible data types. Here is its syntax.
UNION(table_expression1, table_expression2[,table_expression]…)
The <table_expression> arguments are any DAX expression that returns a table.
In our data model we have our products table and a new table containing other products, we can use UNION to merge these two product tables.

INTERSECT: Finding Common Elements
INTERSECT returns the common rows between two tables. This function is useful when we need to identify overlapping data. It’s syntax is simple.
INTERSECT(table_expression1, table_expression2)
The <table_expression> arguments are any DAX expression that returns a table. Duplicated rows are retained. The column names in the resulting table will match the column names in <table_expression1>. The table returned by INTERSECT has lineage based on the column in <table_expression1> regardless of the lineage of the columns in the second table.
Let’s use our new All Products table and INTERSECT to examine what products have sales.
Product IDs with Sales INTERSECT =
INTERSECT(
SELECTCOLUMNS(
'All Products',
"ProdictID",
'All Products'[ProductID]
),
SELECTCOLUMNS(
Sales,
"ProductID",
Sales[ProductID]
)
)

EXCEPT: Identifying Differences
EXCEPT takes two tables and returns the rows from the first table that are not found in the second table. This is useful for finding discrepancies or exclusions between datasets.
The syntax for EXCEPT will look familiar.
EXCEPT(table_expression1, table_expression2)
Where <table_expression> can be any DAX expression that returns a table.
Let’s look at the list of ProductIDs that do not have sales, by modifying the above example using EXCEPT.

Understanding and utilizing UNION for merging data, INTERSECT for finding common data, and EXCEPT for identifying unique data helps enhance our data manipulation and analysis capabilities in Power BI.
DISTINCT: Identifying Unique Values
Identifying unique values in a data set is a common requirement, and the DISTINCT function in DAX provides a straightforward solution. DISTINCT is used to return table that contains the distinct values from a specified column or table. This function can help remove duplicate values and obtain a list of unique entries for further analysis.
The syntax for DISTINCT is simple.
DISTINCT(column)
Here, <column> is the column from which distinct values are to be returned, or an expression that returns a column. When we are using DISTINCT it is important to be aware that the results of this function are affected by the current filter context. For example, if we use DISTINCT to create a measure of the distinct products from our sales table, the result of this measure would change whenever our Sales table was filtered by date or region for example.
Using DISTINCT on a Column
When applied to a column, DISTINCT generates a one column table of unique values from the specified column. For example, we want to create a measure that returns the column of employees that have a sale. For this we can use DISTINCT to get a list of the distinct employee Ids from our Sales table and pass the list to the COUNTROWS functions to produce the count. Here is the expression.
Count of Employee with Sales =
COUNTROWS(
DISTINCT(
Sales[EmployeeID]
)
)

Using DISTINCT on a Table
When used on a table, DISTINCT returns a table with unique rows, effectively removing any duplicated rows. We can use this to examine our Sale table to identify if there are any duplicated sales records. We will create two measures, the first to return the count of rows in our Sales table and the second to return the count of rows of our Sales table using DISTINCT.

Our Count of Sales DISTINCT measure produced a count of our Sales table where each row is unique across all columns in the table. With this compared to our count of Sales we can identify our Sales table has a duplicated record.
TREATAS: Bridging Data Tables
A common challenge we may encounter is linking data from different tables that do not have a direct relationship in the data model. TREATAS in DAX is a powerful function designed to address this issue. It applies the values from one table as filters to another unrelated table. This can be especially useful when we are working with complex models where establishing direct relationships may not be feasible or optimal.
The syntax for TREATAS is as follows:
TREATAS(table_expression, column[, column[, column[,…]]]} )
The arguments of TREATAS are the <table_expression> which is an expression that results in a table, and <column> which is one or more existing columns, it cannot be an expression. The table returned by TREATAS contains all the rows in <column(s)> that are also in <table_expression>. When using TREATAS the number of columns specified must match the number of columns in <table_expression> and they must be in the same order. TREATAS is best used when a relationship does not exist between the tables, if there are multiple relationships between the tables, we should consider using USERELATIONSHIP to specify what relationship to use.
Previously, using SUMMARIZECOLUMNS we created a summary table of sales for the previous year. We now wish to visualize the total sales of this table utilizing a measure that allows the user to filter the value by a selected region.
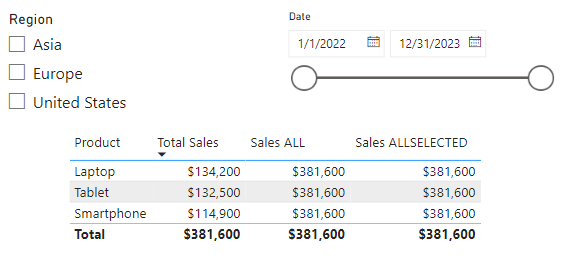
Let’s start by adding a table to visualize our Last Year Sales by Product and Region table, a card visual to visualize the default aggregation of the Total Sales field in this table, and a slicer to allow for selection of a region.

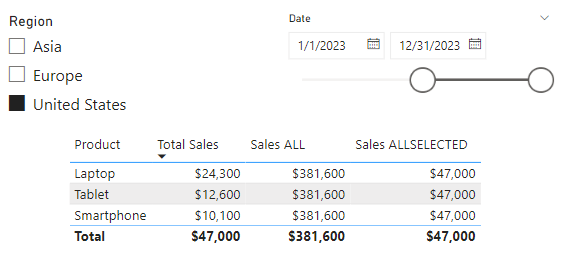
When we select a region in our slicer, an issue becomes clear. The table and Total Sales card visual are not filtered. This is because there is no direct relationship between our Regions table and our Last Year Sales by Product and Region table. Here is how we can create a measure using TREATAS to help solve this issue.
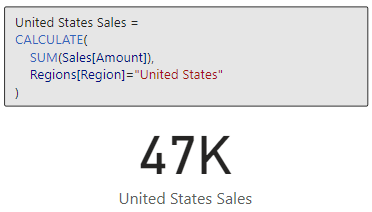
Last Year Sales by Region =
CALCULATE(
SUM('Last Year Sales by Product and Region'[Total Sales]),
TREATAS(
VALUES(Regions[Region]),
'Last Year Sales by Product and Region'[Region]
)
)
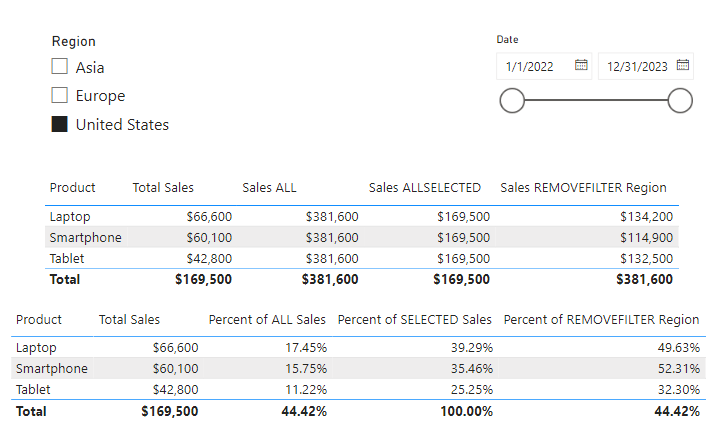
Adding a new card visual to visualize this measure we can see now that the total sales value is filtered by our Region slicer as expected.

By using TREATAS, we can dynamically filter and aggregate data across tables without the need for a physical relationship in the data model. This function is invaluable for creating flexible, context-specific calculations in Power BI.
Wrapping Up: Harnessing the Full Potential of Table Manipulation in DAX
As we wrap up our exploration of table manipulation functions in DAX, it is clear that these tools offer a wealth of possibilities for transforming and understanding our data. The functions we discussed here and many others found in the DAX Reference Guide each serve unique purposes and can be combined in various ways to unlock deeper insights.
Table Manipulation Functions – DAX | Microsoft Learn
Learn more about: Table manipulation functions.
These functions offer flexibility in data manipulation, enabling custom analyses and efficient data modeling. Mastering these functions enhances the power of our reports, making them more insightful and interactive. However, as always, it is important to balance complexity with efficiency to maintain sufficient performance.
Thank you for reading! Stay curious, and until next time, happy learning.

And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment and explore new DAX functions, and challenge yourself with real-world data scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.