Are you ready to take your data analysis to the next level?
Explore the power of calculated measures and columns in Power BI that will revolutionize the way you uncover insights and elevate your Power BI skills.
Introduction
In the world of data analysis, the ability to derive meaningful insights from raw data is crucial. Power BI empowers you to go beyond just the basics and unlock the full potential of your data through calculated measures and columns. These game-changing features allow you to perform complex calculations and create new data points based on existing information. Enabling you to gain deeper insights and make more and better informed decisions.
Calculated Measures
Creating calculated measures in Power BI is a straightforward process. With just a few simple steps, you can unleash a whole new level of analysis. For example, say you have a sales dataset and want to calculate the average unit price of products sold. This can easily be accomplished by creating a calculated measure.
Start by opening Power BI Desktop and navigating to the report or dataset where you want to create the calculated measure. Right-click on the desired table, select New Measure and enter the required formula or expression that defines the calculation. To demonstrate the example above we will enter:
Average Unit Price = AVERAGE(SalesOrderDetail[UnitPrice])

Power BI will instantly calculate the average unit price based on the defined formula.
But wait, there is more!
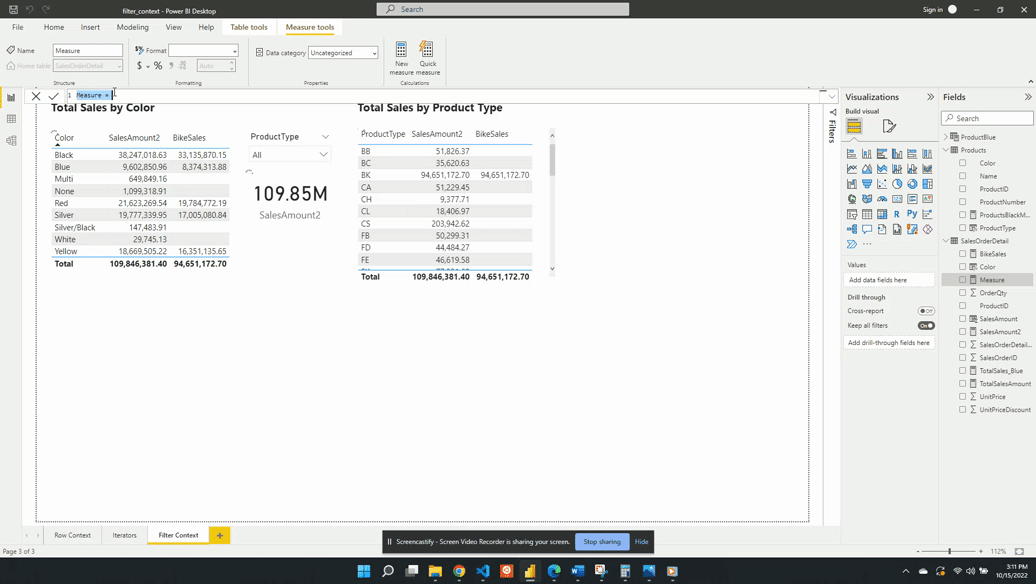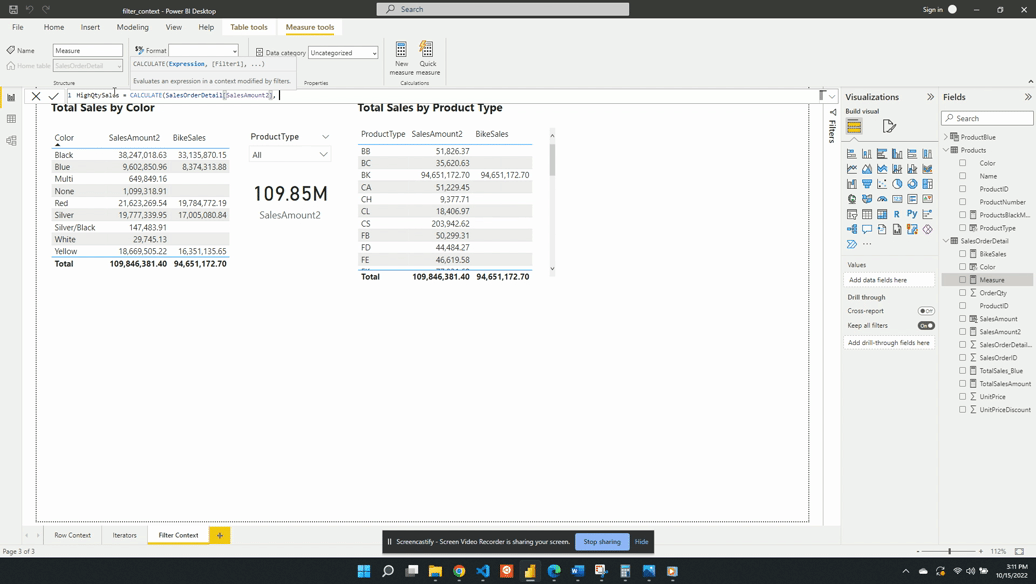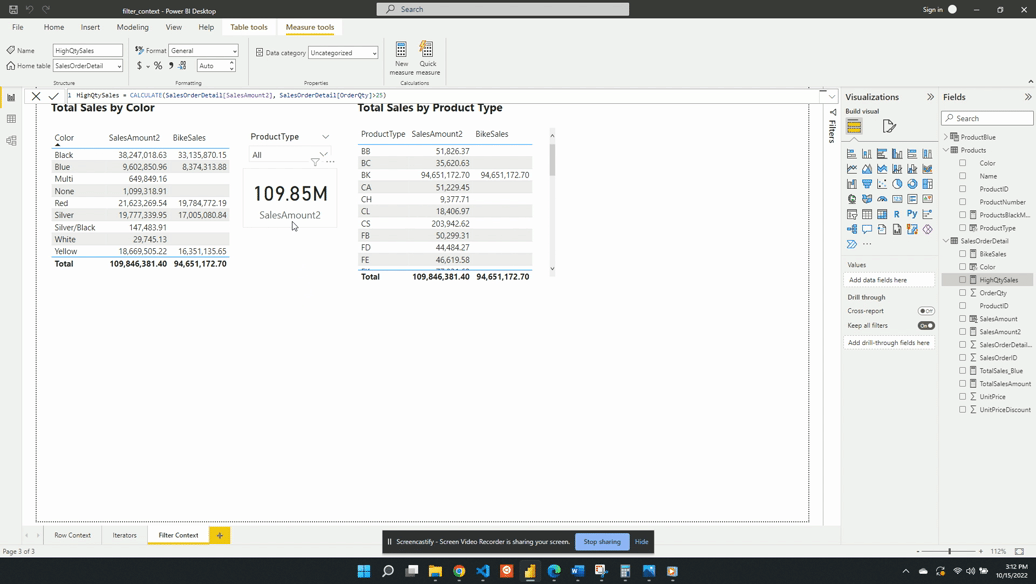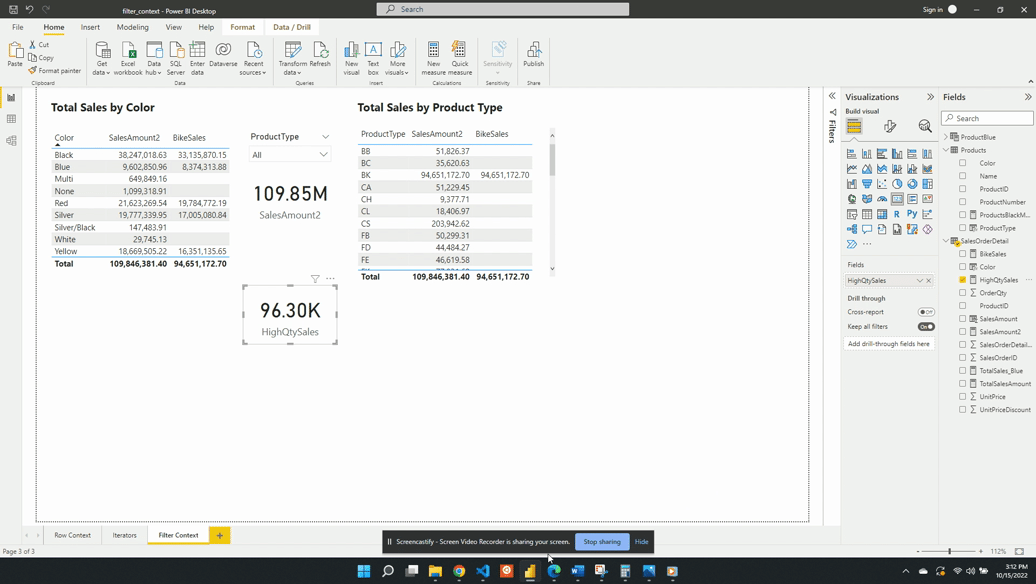
Calculated measures go way beyond just calculating basic aggregations. We can step up our calculated measure game by using DAX iterator functions. Iterator functions are DAX expressions that operate row-by-row, or are in Power BI referred to as having row context. These functions typically end with an X (e.g. SUMX, AVERAGEX).
Iterator functions are DAX expressions that operate row-by-row, in Power BI this is referred to as having row context.
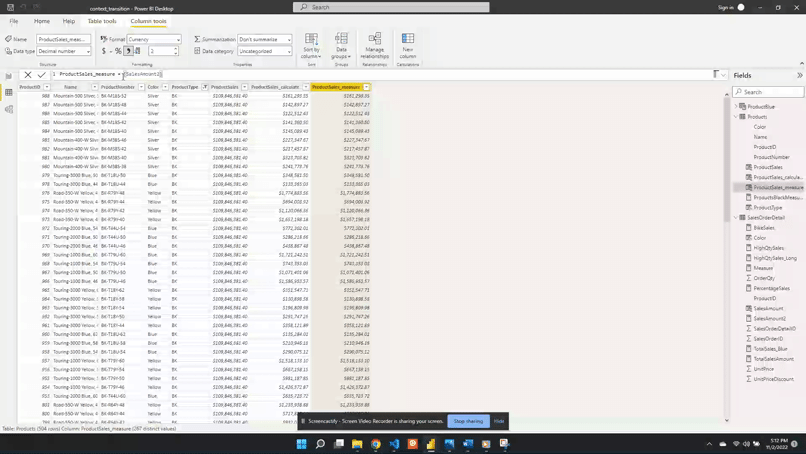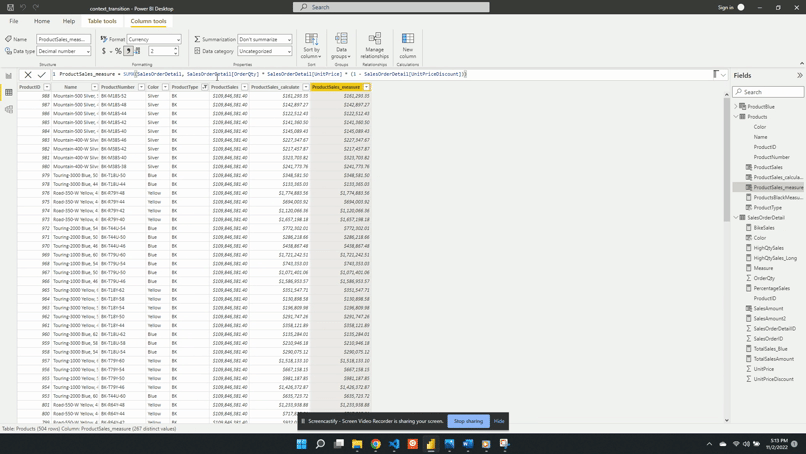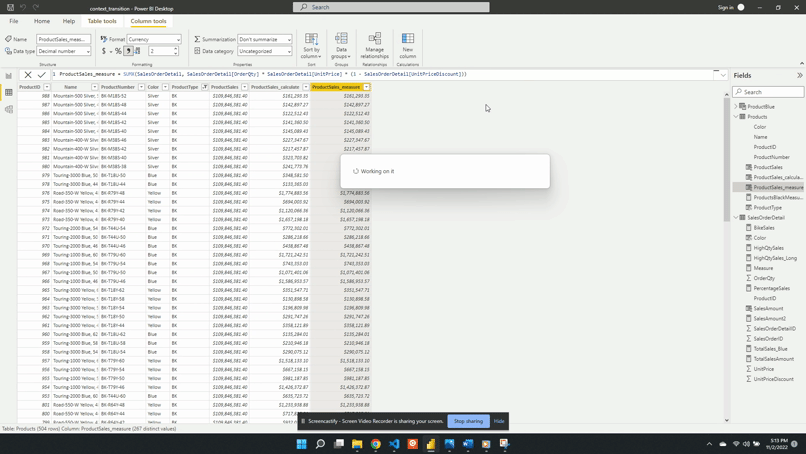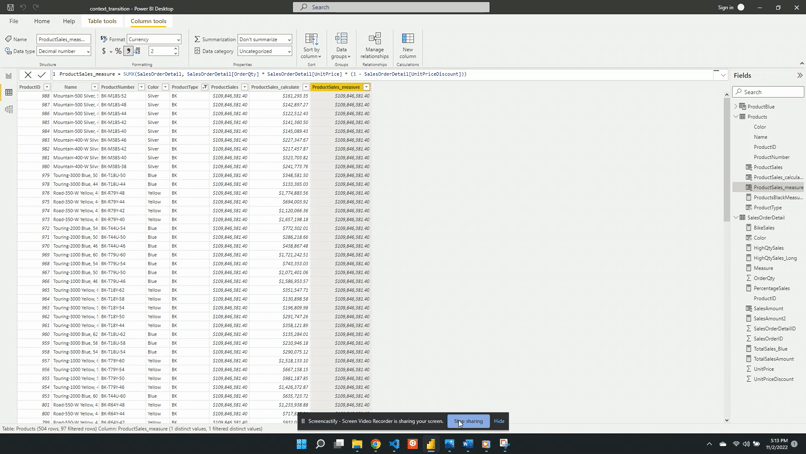
Our Sales table has OrderQty, UnitPrice and UnitPriceDiscount columns but no column for the sales amount. We are interested in this sales amount value and how it trend over time.
To analyze this we can create a new measure Sales Amount defined by the following expression:
SalesAmount =
SUMX(
SalesOrderDetail, SalesOrderDetail[OrderQty] *
SalesOrderDetail[UnitPrice] * (1 -
SalesOrderDetail[UnitPriceDiscount])
)

This calculated measure allows you to gain insights into the overall sales performance and identify patterns or trends over time.
For a deep dive and further exploration of iterator functions check out the Power BI Iterators: Unleashing the Power of Iteration in Power BI Calculations.

Power BI Iterators: Unleashing the Power of Iteration in Power BI Calculations
Iterator Functions — What they are and What they do
Whether it’s aggregating data, calculating ratios, or applying logical functions, Power BI offers a rich set of DAX functions that have got you covered.
Calculated Columns
In addition to calculated measures Power BI also offers the ability to create calculated columns. Calculated column take your data analysis to another level by allowing you to create new data points at the individual row level. The possibilities are endless when you can combine existing columns, apply conditional logic, or generate dynamic values. Let’s consider a products dataset where you have the Product Number which contains a two letter product type code followed by the product number. For your analysis you require an additional column containing just the product type identifier. Calculated columns are well suited to meet this need.
Within Power BI Desktop right-click the table where you want to add the calculated column, select New Column, and define the formula or expression. To extract the first two characters (i.e. the product type code) we will use:
Calculated columns take your data analysis to another level by allowing you to create a new data points at the individual row level.
ProductType = LEFT(Products[ProductNumber],2)

Power BI will extract the first two characters of the Product Number for each row, creating a new Product Type column. This calculated column makes it easier to analyze and filter data based on the product type. Power BI’s intuitive interface and DAX language make this process seamless and approachable.
For more details on calculated measures and columns check out Power BI Row Context: Understanding the Power of Context in Calculations.

Power BI Row Context: Understanding the Power of Context in Calculations
Row Context — What it is, When is it available, and its Implications
The post highlights the key differences between calculated measures and columns and when it is best practice or beneficial to you one method over the other.
Beyond the Basics
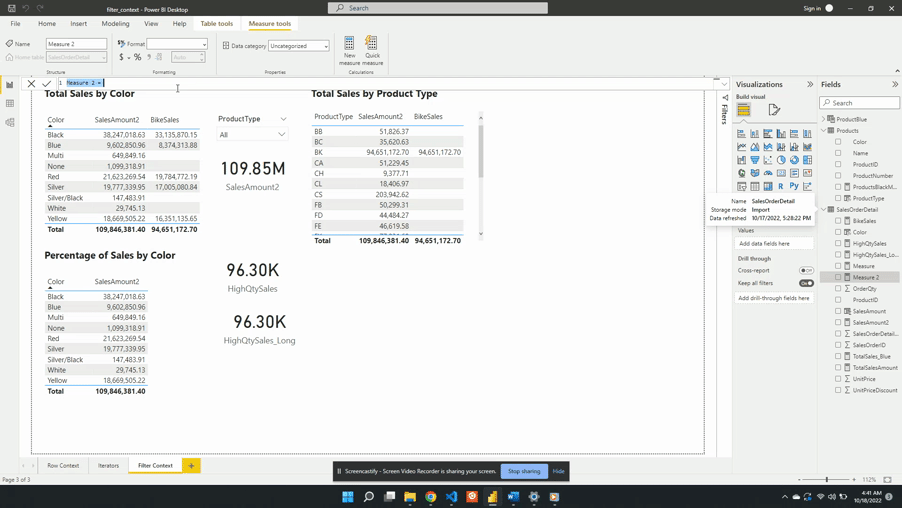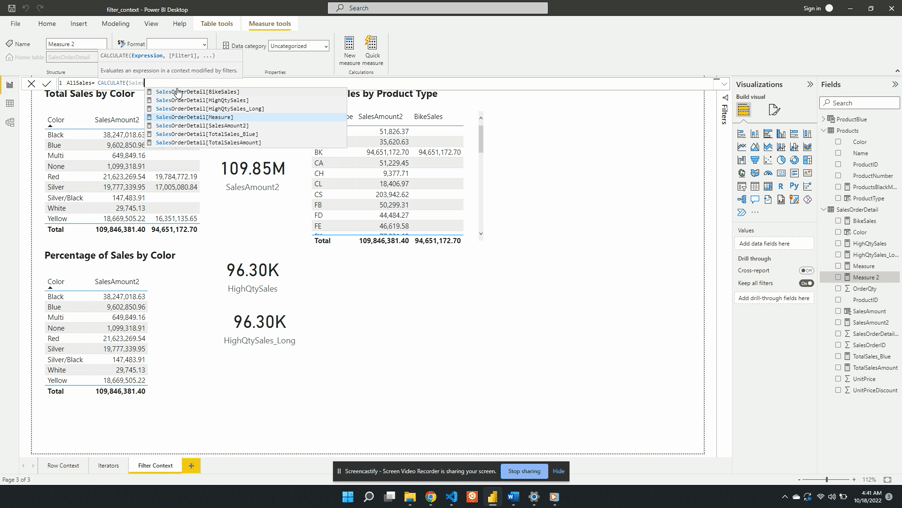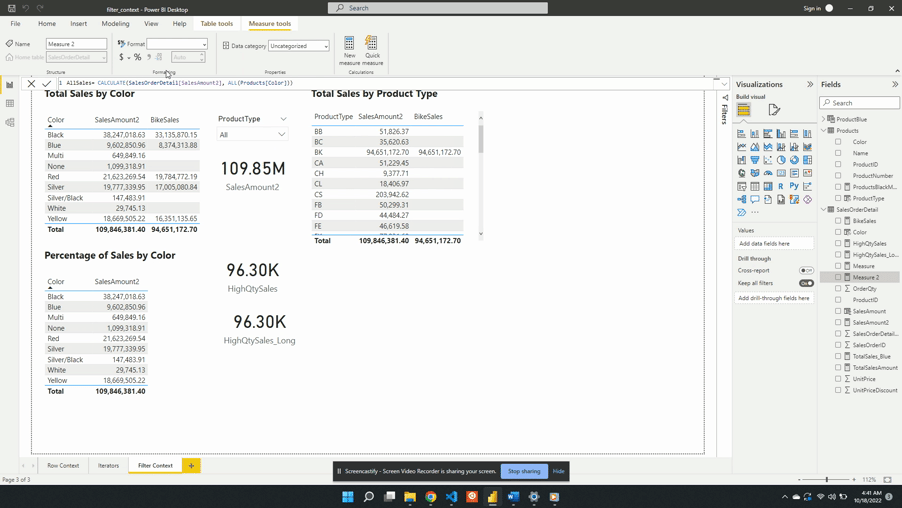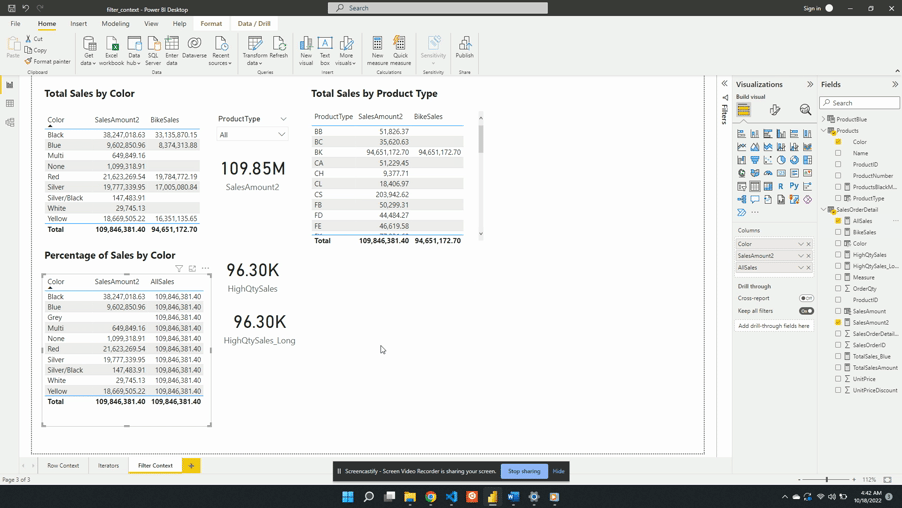
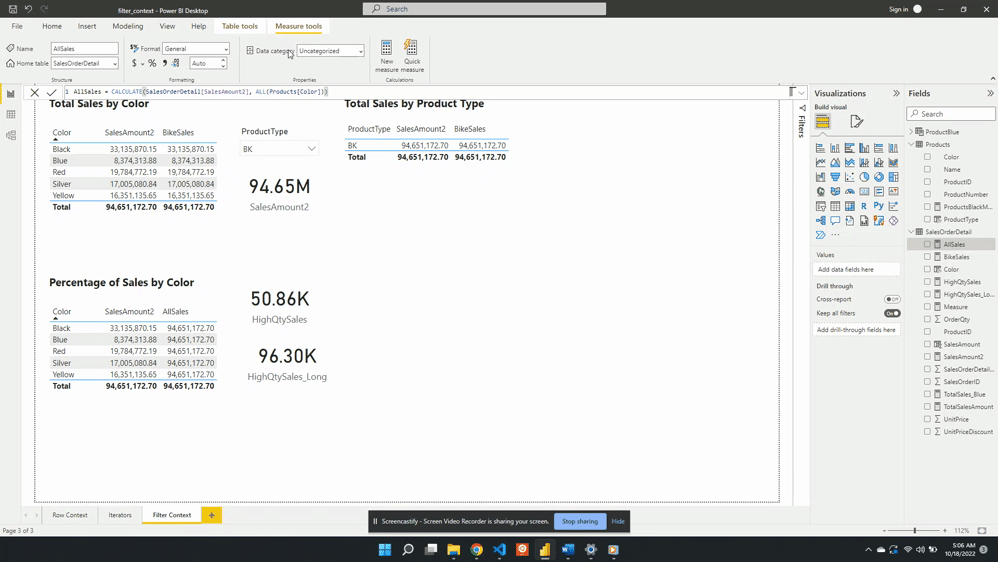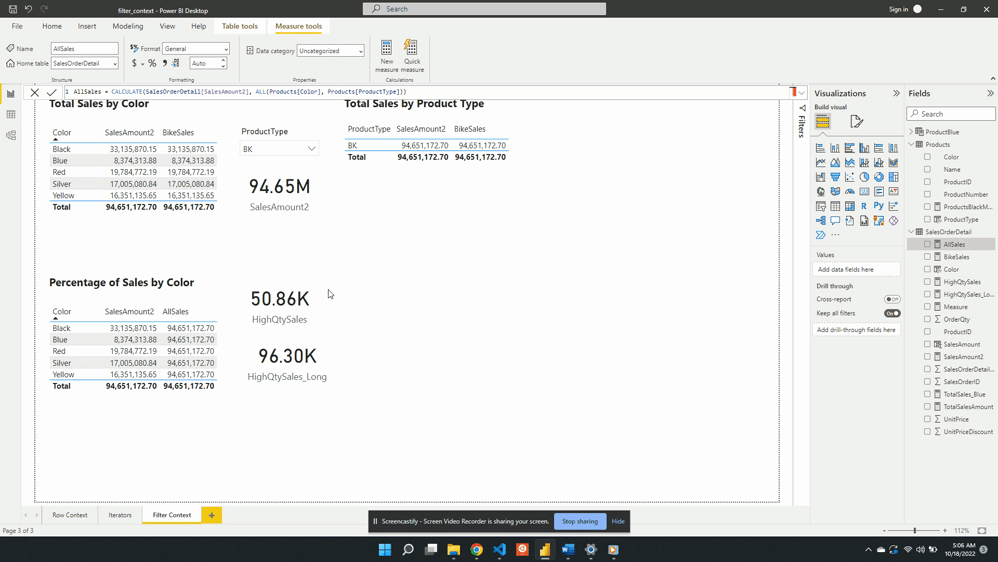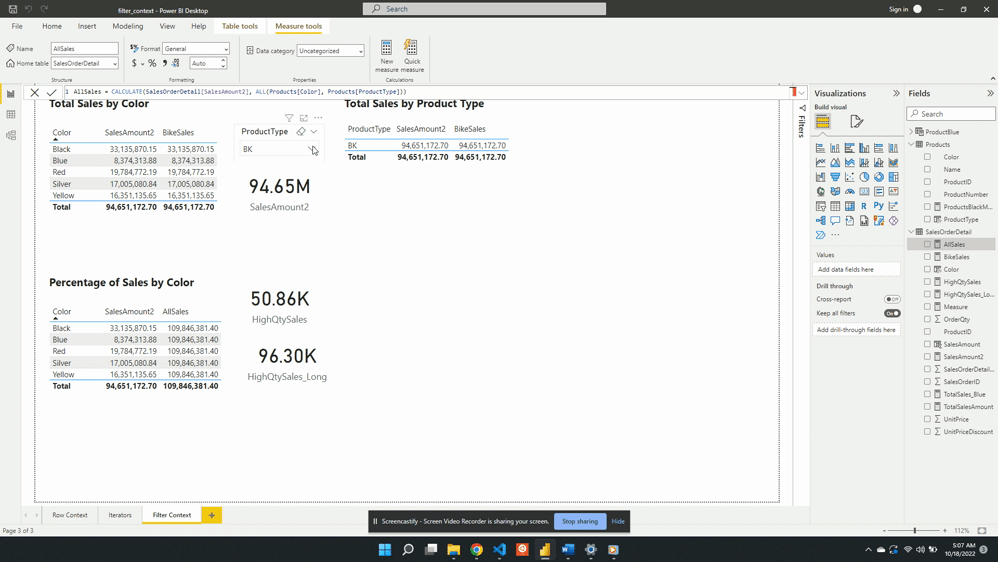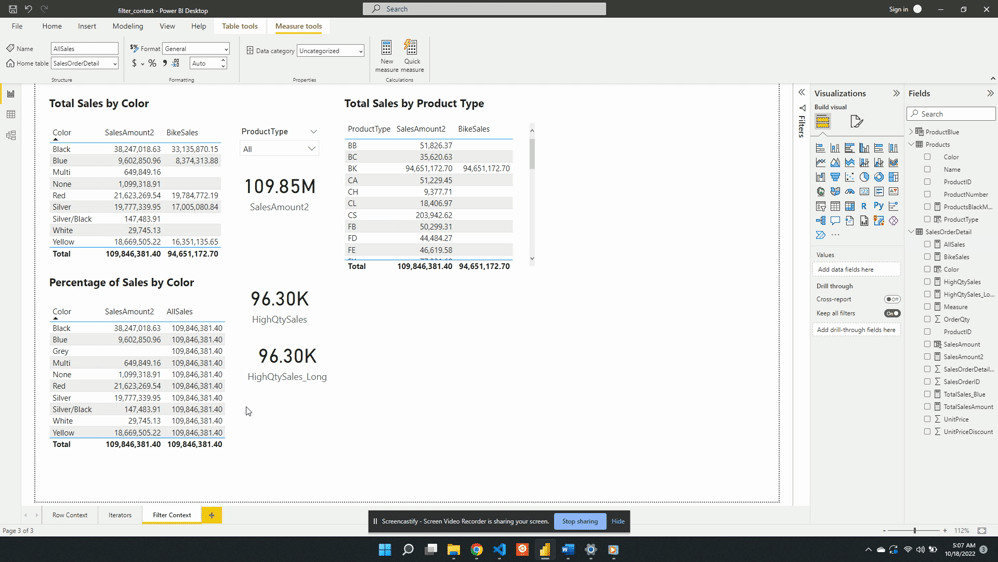
Why limit yourself to basic calculations? Power BI’s calculated measures and columns give you the power to dig deeper into your data. Using complex calculations you can uncover deeper patterns, trends, and correlations that were previously hidden. For example, with our sales data we want to analyze the percentage of total sales for each product type. With Power BI, you can create a calculated measure using the formula:
Percentage Sales =
VAR Sales = SalesOrderDetail[Sales Amount]
VAR AllSales =
CALCULATE(
SalesOrderDetail[Sales Amount],
REMOVEFILTERS(Products[Product Type])
)
RETURN
DIVIDE(Sales, AllSales)

Important Concepts
To continue to elevate your skills in developing calculated measures and columns there are a few concepts to understand. These include row context, filter context, and context transition.
When Power BI evaluates DAX expressions the values the expression can access are limited by what is referred to as the evaluation context. The two fundamental types of evaluation context are row context and filter context.
For further information and a deeper dive into these concepts checkout the following posts:
Power BI Row Context: Understanding the Power of Context in Calculations
Row Context — What it is, When is it available, and its Implications

Power BI Filter Context: Unraveling the Impact of Filters on Calculations
Filter Context – How to create it and its impact on measures
Power BI Context Transition: Navigating the Transition between Row and Filter Contexts
What it is and Why you need to know it
Remember, the flexibility of calculated measures and columns in Power BI allows you to customize and adapt your calculations to suit your specific business needs. With a few simple and well crafted formulas, you can transform your data into meaningful insights and drive data-informed decisions.
Visualize Your Calculations
By incorporating calculated measures and columns into you visualizations you can communicate your data insights effectively. Drag and drop these calculations into your reports and dashboards to display dynamic results that update in real-time. Combine them with filters, slicers, and interactive features to empower users to explore the data and gain deeper insights on their own.
Conclusion
The power of calculated measures and columns lies in their ability to transform data into meaningful insights. They are the key to unlocking the full potential of your data in Power BI.
With the power of calculated measures and columns in Power BI, you have the tools to elevate your data analysis to new heights. Discover the full potential of your data, uncover hidden insights, and make data-driven decisions with confidence. Embrace the simplicity and versatility of calculated measures and columns in Power BI and watch your data analysis thrive. Get ready to embark on your journey to deeper insights and unlock the true power of your data.
Thank you for reading! Stay curious, and until next time, happy learning.

And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment and explore new DAX functions, and challenge yourself with real-world data scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.