Learn how to create a dynamic failure notification framework across Teams channels with a centralized SharePoint setup
Handling errors in Power Automate workflows can be challenging, especially when managing notifications across multiple flows. Adding contact details to each flow can become inefficient and difficult to maintain.
The Microsoft ecosystem offers various options and integrations to address these inefficiencies. In this approach, we will use a SharePoint list to centralize contact information, such as Teams Channel IDs and Teams Tag IDs. This method simplifies management and enhances our failure notification framework.
We will explore two methods. The first involves using Teams shared channels with @mentioning Teams tags to notify a specific group of users within our Power Automate Failure Notifications Teams team. The second method utilizes direct user @mentions in private Teams channels. Both methods employ a solution-aware flow, providing a reusable failure notification framework.
Power Automate Error Handling Best Practices
Before we can send failure notifications using our reusable framework, we first need to identify and handle errors within our workflows. It is essential to incorporate error handling into all our business-critical workflows to ensure that our Power Automate flows are resilient and reliable.
The configure run after setting is crucial for identifying the outcomes of actions within a workflow. It lets us know which actions were successful, failed, skipped, or timed out. By utilizing this feature, we can control how subsequent actions will behave based on the result of prior actions. Customizing these settings allows us to develop flexible and robust error-handling strategies.
Beyond using configure run after, there are important patterns that support effective error management in Power Automate:
Scoped Control (Try-Catch blocks): Grouping actions within the Scope control object aids in managing the outcomes of that set of actions. This method is valuable for isolating distinct parts of our workflow and handling errors effectively.
Parallel Branching: Establishing parallel branches enables certain workflow actions to continue even if others encounter errors. This approach allows us to run error-handling notifications or fallback actions concurrently with the primary process, enhancing the resilience of our flow and preventing interruptions.
Do Until Loop: For situations where actions may need multiple attempts to succeed, the Do Until control object permits us to execute actions until a specified success condition is met or a failure condition triggers our error-handling process.
These patterns collectively improve the reliability of our workflows by incorporating structured and consistent error handling. Identifying errors is just the first step; we must also notify the relevant individuals when a workflow encounters an issue so they can determine if further action or bug fixes are necessary.
Managing error notifications across multiple workflows can be difficult when contact information, such as an email address, is hardcoded into each individual flow. To address this, we will explore centralizing error notification details using a SharePoint list. This approach allows us to separate contact management from the flow logic and definitions.
The Final Solution in Action
Using Teams and Shared Channels with @mentioning Teams tags offers a practical and flexible solution. Teams tags enable us to group team members by their responsibilities, such as Development Team or workflow-specific groups. Using Teams tags makes it easy to alert an entire group using a single @mention tag.
In this example, we implement the Scoped Control (Try-Catch blocks) error handling pattern. This pattern groups a related set of actions into a scope, so if any action fails, we can handle the errors using an associated catch scope.
Here’s a basic flow that is triggered manually and attempts to list the members of a Teams Group chat.

When a non-existent Group chat ID is provided, the List members action will fail. This failure triggers the CATCH scope to execute. The CATCH scope is configured to run only when the TRY scope fails or times out.
When the CATCH scope executes, the flow filters the result of the TRY scope to identify which action failed or timed out using the following expressions:
From: result('TRY_Teams_list_members_made_to_fail')
Criteria: @or(equals(item()?['status'], 'Failed'), equals(item()?['status'], 'TimedOut'))

Next, the flow utilizes the reusable notification framework to send a notification to Teams identifying that an error has occurred and providing details of the error message. We use the Run a Child Flow action and select our reusable error notification workflow for this purpose. This workflow requires three inputs:
workflowDetails: string(workflow())
errorMessage: string(outputs('Filter_TRY_Teams_list_member_result')?['body'])
scopeName: manually entered
When this workflow is triggered, and the TRY scope fails, we receive a Teams notification dynamically sent to the appropriate channel within our Power Automate Failure Notification Team, alerting the necessary individuals using the Dev Team Teams tag and direct @mentioning the technical contact.

The advantage of this approach and framework is that the notification solution only needs to be built once, allowing it to be reused by any of our solution-aware and business-critical workflows that require error notifications.
Additionally, we can manage the individuals alerted by managing the members assigned to each Teams tag or by updating the technical and functional contact details within our SharePoint list. All these updates can be made without altering the underlying workflow.
Continue reading for more details on how to set up and build this error notification framework. This post will cover how the Power Automate Failure Notifications Teams team was set up, provide resources on Teams tags, demonstrate how to create and populate a centralized SharePoint list for the required notification details, and finally, outline the construction of the failure notification workflow.
Setting Up Teams
Our error notification solution utilizes a private Microsoft Team, which can consist of both shared and private channels.
Shared channels are a convenient and flexible option for workflows that are not sensitive in nature. By using shared channels, we can take advantage of the List all tags Teams action to notify a group with a single @mention in our error notifications.
For additional information on managing and using Teams tags, see the resources below:
Microsoft Learn – Manage tags in Microsoft Teams
Microsoft Support – Using tags in Microsoft Teams
Private channels should be used when the workflow involves more sensitive information or when error notifications need to be restricted to a specific subset of team members. In this case, the error notifications target specific individuals by using direct user @mentions.

Centralized Error Notifications Details with SharePoint
To improve the maintainability of our error notifications, we will centralize the storage of key information using a SharePoint list. This approach enables us to store essential details, such as functional and technical contacts, Teams channel IDs, Teams Tag IDs, workflow IDs, and workflow names in one location, making it easy to reference this information in our error notification workflow.
The SharePoint list will serve as a single source for all required flow-related details for our notification system. Each entry in the list corresponds to a specific flow. This centralized repository minimizes the need for hardcoded values. When teams or contact details change, we can simply update the SharePoint list without the need to modify each individual flow.
Steps to Create the SharePoint List
Create a New List: In SharePoint, create a new list with a descriptive name and an appropriate description.
Add Required Columns: Include all necessary required and optional columns to the new SharePoint list.
FlowDisplayName: identifies the specific flow that utilizes the error notification system we are creating.
FlowId: unique identifier for the workflow associated with the error notification system.
Technical Contact: the primary person responsible for technical oversight who will be notified of any errors.
Functional Contact: secondary contact, usually involved in business processes or operational roles.
TeamsChannelName: name of the Teams Channel where error notifications will be sent.
TeamsChannelId: unique identifier for the Teams Channel that the flow uses to direct notifications.
TeamsTagId: this field is relevant only for shared channel notifications and contains the ID of the Teams Tag used to notify specific groups or individuals.

Populate the List with Flow Details
Our failure notification system will send alerts using the Post message in a chat or channel action. When we add this action to our flow, we can use the drop-down menus to manually select which channel within our Power Automate Failure Notifications team should receive the message.

However, it’s important to note that the Channel selection displays the channel name for convenience. Using the peak code option, we can see that the action utilizes the Channel ID.
parameters": {
"poster": "Flow bot",
"location": "Channel",
"body/recipient/groupId": "00000000-0000-0000-0000-000000000000",
"body/recipient/channelId": "00:00000000000000000000000000000000@thread.tacv2",
"body/messageBody": ""
}The same applies when using the Get a @mention token for a tag. To dynamically retrieve the token, we need the Tag ID, not just the Tag name.
These key pieces of information are essential for our Failure Notification solution to dynamically post messages to different channels or @mention different tags within our Failure Notification team.
While there are various methods, such as peek code, to manually find the required values, this can become inefficient as the number of flows increases. We can streamline this process by creating a SharePoint Setup workflow within our Failure Notification solution.
This workflow is designed to populate the SharePoint list with the details necessary for the dynamic error notification framework. By automatically retrieving the relevant Teams channel information and Teams tag IDs, it ensures that all the required data is captured and stored in the SharePoint list for use in error notification flows.
SharePoint Set Up Workflow
This workflow has a manual trigger and allows us to run the setup as needed by calling it using the Run a Child Flow action when we want to add our error notifications to a workflow.
The inputs consist of 6 required string inputs and 1 optional string input.

channelDisplayName (required): the channel display name that appears in Teams.
workflowId (required): the flow ID to which we add our error notifications. We can use the expression: workflow()?['name'].
workflowDisplayName (required): the display name of the flow to which we are adding our error notifications. We can manually type in the name or use the expression: workflow()?['flowDisplayName'].
technicalContact (required): the email for the technical contact.
functionalContact (required): the email for the functional contact.
workflowEnvironment (required): the environment the flow we are adding the error handling notifications to is running in. We can use the expression: workflow()?['tags']?['environmentName']
tagName (optional): the display name of the Teams tag, which is manually entered. This input is optional because the error notification solution can be used for Shared or Private Teams channels. However, @mentioning a Teams tag is only utilized for Shared channels.
Following the trigger, we initialize two string variables. The first ChannelId and the second TagId.

Get the Teams Channel ID
The next set of actions lists all the channels for a specified Team and uses the channelDisplayName input to extract the ID for the channel and set the ChannelId variable.

The Teams List channels action retrieves a list of all available channels in our Power Automate Failure Notifications Teams team. The Filter array action then filters this list based on the channelDisplayName input parameter.
The flow then attempts to set the ChannelId variable using the expression:outputs('Filter_array_to_input_teams_channel')['body'][0]?['id'].
However, if the output body of the Filter array action is empty, setting the variable will fail. To address this, we add an action to handle this failure and set the ChannelId to “NOT FOUND”. This indicates that no channel within our Power Automate Failure Notifications team matches the provided input value.
To achieve this, we use the Configure run after setting mentioned earlier in the post and set this action to execute only when the TRY Set ChannelId action fails.

Get the Teams Tag ID
After extracting the Teams Channel ID, the flow has a series of similar actions to extract the Tag ID.

Create an item on the SharePoint List
Lastly, the flow creates a new item on our supporting SharePoint list using the flow-specific inputs to store all the required information for our error notification solution.

Reusable Error Notification Flow Architecture
As the number of our workflows increases, a common challenge is developing a consistent and scalable error notification system. Instead of creating a new notification process for each workflow, we can leverage reusable solution-aware flows across multiple workflows within our environment. This approach minimizes duplication and streamlines our error notification processes.
Flow Structure for Reusable Notifications
The reusable notification flow is triggered when an error occurs in another workflow using the Run a Child Flow action and providing the required inputs.
The notification workflow parses the details of the workflow that encounters an error, creates an HTML table containing the details of the error that occurred, and then sends the notification using the centralized SharePoint list created in the previous section and dynamically alerts the appropriate individuals.

Trigger Inputs & Data Operations
We can catch and notify responsible parties that an error occurred in a workflow by calling this notification flow, using the Run a Child Flow action, and providing the workflowDetails, errorMessage, and scropeName.
workflowDetails: string(workflow())
errorMessage: string(outputs(<FILTER_TRY_SCOPE_ACTION>)
scopeName: manually entered

After the trigger, we carry out two data operations. First, we parse the workflowDetails using the Parse JSON action and the expression json(triggerBody()?['text']) for the Content. Then, we create an HTML table using the information provided by our errorMessage input.

For the Create HTML table action, we use the following expressions for the inputs:
From: json(triggerBody()?['text_1'])
Scope: triggerBody()?['text_2'])
Action: item()?['name']
Message: concat(item()?['error']?['message'], item()?['outputs']?['body']?['error']?['message'],item()?['body']?['message'])
Retrieve Contact Information
The notification flow queries the centralized SharePoint list to retrieve the necessary contact details and Teams information associated with the workflow that encountered the error.
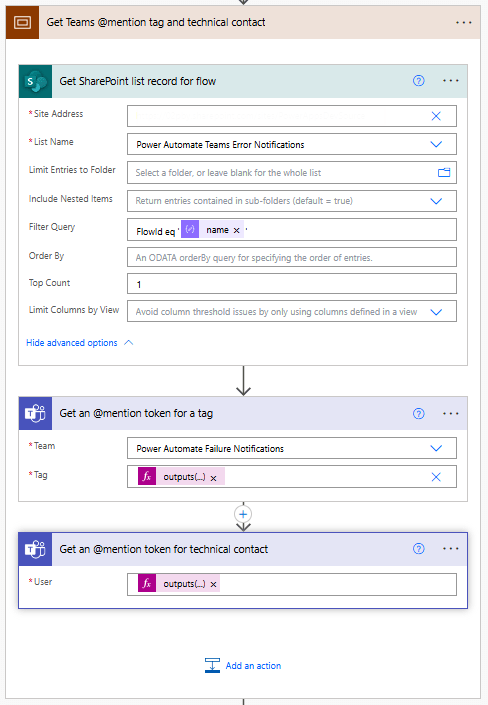
We begin this subprocess by using the SharePoint Get items action with the Filter Query:FlowId eq 'body('Parse_workflowDetails_JSON')?['name']'.
Since each FlowID on our list should have only 1 record, we set the Top Count to 1.
Then, if our Power Automate Failure Notification Teams team uses Shared Channels, we use the Teams Get an @mention token for a tag and pass it the TagId stored within our SharePoint list using:outputs('Get_SharePoint_list_record_for_flow')?['body/value'][0]?['TagId'].
If the notification team uses private channels, this action can be excluded.
Lastly, for both Shared and Private channel notifications, we use the Teams Get an @mention token for user action to get the token for the technical contact stored within our SharePoint list using:outputs('Get_SharePoint_list_record_for_flow')?['body/value'][0]?['TechnicalContact']?['Email']
Send Teams Notification
Once we have retrieved the required contact details from SharePoint and Teams, the flow sends a notification to the appropriate Teams channel, notifying the relevant individuals. For Shared Channels, the message uses the @mention token for a Teams tag. If Private Channels are utilized, this should be removed from the flow and message.
Additionally, the message can be posted as the Flow bot when using Shared channels. However, when using Private channels, the message must be posted as User.

The flow dynamically sets the Channel using the ChannelId stored within our SharePoint list with the expression:outputs('Get_SharePoint_list_record_for_flow')?['body/value'][0]?['ChannelId'].
The message begins by identifying the workflow in which an error was encountered and the environment in which it is running.
Error reported in workflow:body('Parse_workflowDetails_JSON')?['tags']?['flowDisplayName'] {body('Parse_workflowDetails_JSON')?['tags']?['environmentName']}
Then, the message adds the HTML table created with the error message details using the following expression: body('Create_HTML_table_with_error_action_and_message').
Finally, it notifies the contacts for the workflow by using the @mention tokens for the Teams tag and/or the technical contact. The message also provides the details on the functional contact using the expression:outputs('Get_SharePoint_list_record_for_flow')?['body/value'][0]?['FunctionalContact']?['Email']
The notification process sends an informative and targeted message, ensuring all the appropriate individuals are alerted that an error has occurred within a workflow.

Reusability
This architecture enables us to develop a single workflow that can trigger error notifications for any new workflows, making our error handling and notification process scalable and more efficient.
By using this approach, we can avoid hardcoding notification logic and contact details in each of our workflows. Instead, we can centrally manage all error notifications. This reduces the time and effort needed to maintain consistent error notifications across multiple workflows.
Wrapping Up
This Power Automate error notification framework provides a scalable solution for managing notifications by centralizing contact information in a SharePoint list and leveraging solution-aware flows. Setting up a single, reusable notification flow eliminates the need to hardcode contact details within each workflow, making maintenance and updates more efficient.
The framework targeted two notification methods: Shared Teams channels with tags and Private Teams channels with direct mentions. This system ensures error notifications are delivered to the right individuals based on context and need.
Shared Channels with Teams Tags
This approach sends notifications to a shared Teams channel, with Teams tags allowing us to notify a group of individuals (such as a “Dev Team”) using a single @mention.
How It Works: The notification flow retrieves tag and channel details from the SharePoint list. It then posts the error notification to the shared channel, @mentioning the relevant Teams tag to ensure all tag members are alerted.
Advantages: This method is scalable and easy to manage. Team members can be added or removed from tags within Teams, so updates don’t require changes to the flow definition. This is ideal for notifying larger groups or managing frequent role changes.
Private Channels with Direct @Mentions
Private channels are used to send notifications directly alerting a technical contact when workflow and error details should not be visible to the entire Team.
How It Works: The flow dynamically retrieves contact details from the SharePoint list and posts the error notification to the private channel, mentioning the designated technical contact.
Advantages: This approach provides greater control over the visibility of the notifications, as access is restricted to only those users included in the private channel.
Each of these approaches is flexible and reusable across multiple workflows, simplifying the process of managing error notifications while ensuring messages reach the appropriate individuals based on the notification requirements.
Thank you for reading! Stay curious, and until next time, happy learning.

And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment, explore, and challenge yourself with real-world scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.