User-Centric Design: Next level reporting with interactive navigation for an enhanced user experience.
An essential aspect of any multi-page report is an effective and intuitive way to navigate between the various report pages. A well-designed navigational element in our Power BI reports enhances our users’ experience and guides them to the data and visualizations they require.
Streamlined report navigation with built-in tools to achieve functional, maintainable, and engaging navigation in Power BI reports.
For those interested in implementing the navigation element presented in this post, there are 2-, 3-, 4-, and 5-page templates available for download, with more details at the end of the post.
Welcome back to another Design Meets Data exploration focused on interactive report navigation in Power BI. In the first part, we dove into using Figma to design and develop a user-friendly report interface.
Now, it is time to shift our focus towards leveraging Power BI’s native arsenal of tools, primarily bookmarks, buttons, and tool tips, to achieve similar, if not enhanced, functionalities.
Why go native? Utilizing Power BI’s built-in tools streamlines support and maintenance and provides a reduction in external complexities and dependencies. Plus, staying within a single platform makes it easier to manage and update our reports.
This post will highlight the nuances of Power BI’s navigation capabilities. It will demonstrate how to replicate the interactive navigation from Design Meets Data: A Guide to Building Interactive Power BI Report Navigation using tools available directly within Power BI. These tools will help simplify our report while maintaining an engaging and interactive navigational element.
Let’s get started!
Setting the Stage with Power BI Navigation
Before diving into the details, let’s step back with a quick refresher on the Power BI tools that we can leverage for crafting our report navigation. Power BI is designed to support complex reporting requirements with ease, thanks to features like bookmarks, buttons, and tooltips that can be intricately configured to guide our users through our data seamlessly.
Bookmarks
Bookmarks in Power BI save various states of a report page, allowing users to switch views or data contexts with a single click. We can use bookmarks to allow our users to toggle between different data filters or visual representations without losing context or having to navigate multiple pages.
For our navigational element, bookmarks will be key to creating the collapsing and expanding functionality. To create a bookmark, we get the report page looking just right, then add a bookmark to save the report state in the bookmark pane.
The new bookmark can now act as a restore point, bringing the user back to this specific view whenever it is selected. To keep our bookmarks organized it is best to rename them with a description name, generally including the report page and an indication of what the bookmark is used for (e.g. Page1-NavExpanded).
Buttons
Buttons take interactivity to the next level. We can use buttons to trigger various events, such as bookmarks, and also serve as navigation aids within the report. Buttons within our Power BI reports can be styled and configured to react dynamically to user interactions.
To create a button, we simply add the button object from the Insert ribbon onto the report canvas. Power BI offers a variety of button styles, such as a blank button for custom designs, or predefined icons for common actions like reset, back, or informational buttons.
Each button can be styled to match our report’s theme, including colors, text, and much more. Another key property to configure is the button action. Using this, we can define whether the button should direct our users to a different report page, switch the report context to a different bookmark, or another one of the many options available.
Tooltips
Tooltips in Power BI can provide simple text hints, but when properly utilized, they can provide additional insights or contextual data relevant to specific visuals without cluttering the canvas. This provides detail when required while keeping our reports clean and simple.
Power BI allows us to customize tooltips to show detailed information, including additional visuals. This can turn each tooltip into a tool to provide context or additional layers of data related to a report visual when a user hovers over the element.
By effectively using tooltips we transform user interaction from just viewing to an engaging, exploratory experience. This boosts the usability of our reports and ensures that users can make informed decisions based on the data view provided.
The Navigation Framework
Now that we have explored some details of the elements used to create our navigation, let’s dive into building the navigational framework. We will craft a minimalistic navigation on the left-hand side of our report, with the functionality to expand when requested by user interaction. This approach to our navigation is focused on making the navigation pane both compact and informative, ensuring that it does not overpower the content of the report.
In the Design Meets Data: A Guide to Building Interactive Power BI Report Navigation blog post the navigational element was built using Figma. Although Figma is a powerful and approachable design tool, in this guide, we will explore creating a similar navigation pane using native Power BI tools and elements. We will use Power BI’s shapes, buttons, and bookmarks to construct the framework and functionality.
The Navigation Pane Base Elements
We will start by creating the navigation pane by adding the base elements. In this compact and expandable design, this includes the background of the navigation pane, which will contain the page navigation and menu icons.
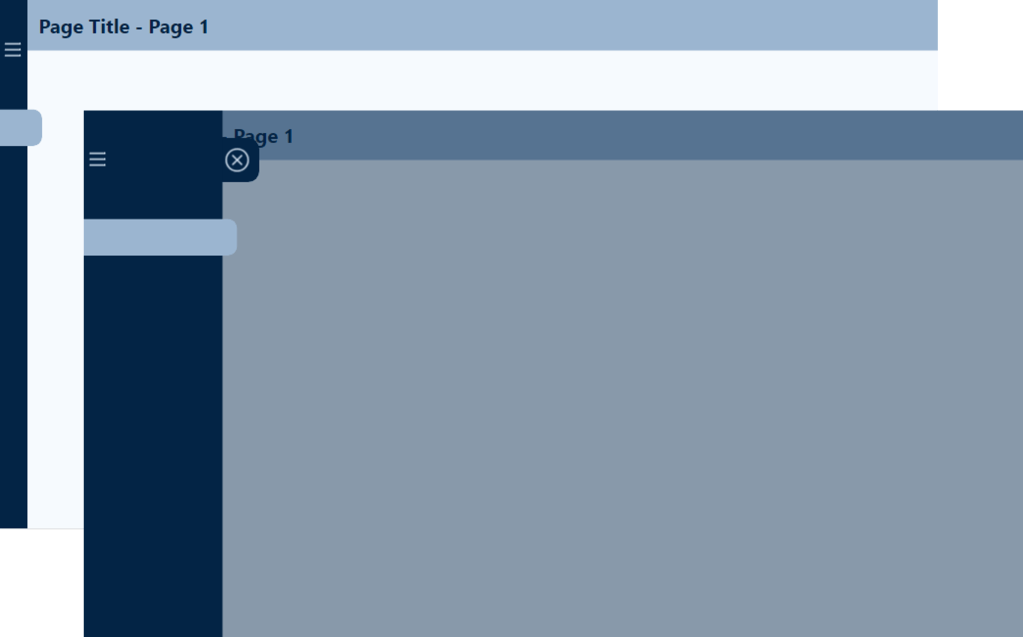
Collapsed Navigation Pane
The base of the navigation consists of three main components that we add to our Power BI report to start building our interactive navigational element.
The collapsed navigation pane starts by adding the shape of the pane itself. The color is set to theme color 1, 50% darker of the Power BI theme. Using the theme color will help our navigation remain dynamic when changing Power BI themes.
The next base element is the menu icon, which expands and collapses our navigation pane. The button is configured to slightly darken when hovered over and darken further when pressed. Additionally, when the button is disabled, the icon color is set to the same color as the navigation pane and is used to contrast the current page indicator bar. This configuration is used for all buttons contained within the navigation pane (both the bookmark and page navigation buttons).
The last base element is the current page indicator. This is a lighter-colored (theme color 1, 60% lighter) rectangle tab that clearly indicates what page in the navigation pane is currently being viewed.
Here is the collapsed navigation pane containing the base elements.
Expanded Navigation Pane
The expanded navigation consists of the same base elements, with the addition of a close icon, and a click shield to prevent the user from interacting with the report visuals when the navigation is expanded.
The additional elements of the expanded menu provide the user with multiple methods to collapse the navigation pane. The close (X) button is added as a flyout from the base navigation pane background, so it is easily identifiable.
When the navigation pane is expanded, we want to prevent users from interacting with the report visuals. To achieve this, we use a partially transparent rectangle to serve as a click shield. If the user clicks anywhere on the report page outside of the navigation pane, the navigation pane will collapse returning the user to the collapsed report view.
Navigation Bookmarks
The last base element required for the interactive navigation is creating the required bookmarks to transition between the collapsed and expanded view. This is done by creating two bookmarks to store each of the required report page views, Page1-Default-NavCollapsed and Page1-NavExpanded.
We can now build on these base elements and bring our navigation to life with Power BI buttons and interactive features.
Navigation Interactive Features
The interactive features in the navigation pane consist of two types of buttons: (1) bookmark buttons and (2) page navigation buttons.
Expanding and Collapsing the Navigation Pane
The previous section added the base elements of the navigation pane which included a menu icon on both the collapsed and expanded navigation panes, and a close button and click shield on the expanded navigation screen.
Building the interactive elements of the navigation starts by assigning actions to each of these bookmark buttons, allowing the user to expand and collapse the navigation pane seamlessly.
The action property for each of these buttons is set to a bookmark type, with the appropriate bookmark selected. For example, for the menu icon button on the collapsed menu, the bookmark selected corresponds to the expanded navigation bookmark. This way, when a user selects this button on the collapsed navigation, it expands, revealing the additional information provided on the expanded navigation pane.
Page Navigation Buttons
The last element to add to the report navigation is the report page navigation buttons.
Each report page button is a blank button configured and formatted to meet the report’s requirements. For this report, each page button contains a circular numbered icon to indicate the report page it navigates to. When the navigation is expanded, an additional text element displays the report page title.
At the end of this post, there are details on obtaining templates that implement this report navigational element. The templates are fully customizable, so they will come with the numbered icons and default page titles, but these can simply be updated to match the aesthetic of any reporting needs.
Wrapping Up: Elevating Your Power BI Reports with Interactive Navigation
As Power BI continues to evolve, integrating more engaging and interactive elements into our reports will become crucial for creating dynamic and user-centric reports. The transition from static to interactive reports empowers our users to explore data in a more meaningful and memorable way. By leveraging bookmarks, buttons, and tooltips, we can transform our reports from a simple presentation of data into engaging, intuitive, and powerful analytical tools.
For those eager to implement the navigational element outlined in this post, there are 2-, 3-, 4-, and 5-page templates available for download. Each template has all the functionality built in, requiring only updating the button icons, if necessary, to better align with your reporting needs.
You will get individual template files for a 2-, 3-, 4-, and 5-page report provided in the PBIX, PBIT, and PBIP (12 total files) formats!
Thank you for reading! Stay curious, and until next time, happy learning.
And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment, explore, and challenge yourself with real-world scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.
Bridge the gap between data chaos and clarity with the strategic use of Power BI Logical Functions
The missing piece to decoding our data and unlocking its full potential is often the strategic application of DAX Logical Functions. These functions are pivotal in dissecting complex datasets, applying business logic, and enabling a nuanced approach to data analysis that goes beyond surface-level insights. Better understanding DAX Logical Functions allows us to create more sophisticated data models that respond with agility to analytical queries, turning abstract numbers into actionable insights.
In this post we will explore this group of functions and how we can leverage them within Power BI. We will dive in and see how we can transform our data analysis from a mere task into an insightful journey, ensuring that every decision is informed, every strategy is data-driven, and every report illuminates a path to action.
The Logical Side of DAX: Unveiling Power BI’s Brain
Diving into the logical side of DAX is where everything begins to become clear. Logical functions are the logical brain behind Power BI’s ability to make decisions. Just like we process information to decide between right and wrong, DAX logical functions sift through our data to determine truth values: true or false.
Functions such as IF, AND, OR, NOT, and TRUE/FALSE, are the building blocks for creating dynamic reports. These functions allow us to set up conditions that our data must meet, enabling a level of interaction and decision-making that is both powerful and nuanced. Whether we are determining if sales targets were hit or filtering data based on specific criteria, logical functions are our go-to tools for making sense of the numbers.
For details on these functions and many others visit the DAX Function Reference documentation.
The logical functions in DAX can go far beyond the basics. The real power happens when we start combining these functions to reflect complex business logic. Each function plays its role and when used in combination correctly we can implement complex logic scenarios.
For those eager to start experimenting there is a Power BI report pre-loaded with the same data used in this post ready for you! So don’t just read, follow along and get hands-on with DAX in Power BI. Get a copy of the sample data report here:
This dynamic repository is the perfect place to enhance your learning journey.
Understanding DAX Logical Functions: A Beginner’s Guide
When starting our journey with DAX logical functions we will begin to understand the unique role of each function within our DAX expressions. Among these functions, the IF function stands out as the decision-making cornerstone.
The IF function tests a condition, returning one result if the condition is TRUE, and another if FALSE. Here is its syntax.
IF(logical_test, value_if_true, value_if_false)
The logical_test parameter is any value or expression that can be evaluated to TRUE or FALSE, and then the value_if_true is the value that is returned if logical_test is TRUE, and the value_if_false is optional and is the value returned when logical_test is FALSE. When value_if_false is omitted, BLANK is returned when the logical_test is FALSE.
Let’s say we want to identify which sales have an amount that exceeds $5,000. To do this we can add a new calculated column to our Sales table with the following expression.
This expression will evaluate each sale in our Sales table, labeling each sale as either “Above Target” or “Below Target” based on the Sales[Amount].
The beauty of starting our journey with IF lies in its simplicity and versatility. While we continue to explore logical functions, it won’t be long before we encounter TRUE/FALSE.
As we saw with the IF function these values help guide our DAX expressions, they are also their own DAX function. These two functions are the DAX way of saying yes (TRUE) or no (FALSE), often used within other logical functions or conditions to express a clear binary choice.
These functions are as straightforward as they sound and do not require any parameters. When used with other functions or conditional expressions we typically use these to explicitly return TRUE or FALSE values.
For example, we can create another calculated column to check if a sale is a high value sale with an amount greater than $9,000.
High Value Sale =
IF(
Sales[Amount] > 9000,
TRUE,
FALSE
)
This simple expression checks if the sales amount exceeds $9,000, marking each record as TRUE if so, or FALSE otherwise.
Together IF and TRUE/FALSE form the foundation of logical expressions in DAX, setting the stage for more complex decision-making analysis. Think of these functions as essential for our logical analysis, but just the beginning of what is possible.
The Gateway to DAX Logic: Exploring IF with AND, OR, and NOT
The IF function is much more than just making simple true or false distinctions; it helps us unlock the nuanced layers of our data, guiding us through the paths our analysis can take. By effectively leveraging this function we can craft detailed narratives from our datasets.
We are tasked with setting sales targets for each region. The goal is to base these targets on a percent change seen in the previous year. Depending on whether a region experienced a growth or decline, the sales target for the current year is set accordingly.
In this measure we make use of three other measures within our model. We calculate the total sales for the previous year (Total Sales (CY-1)), and the year before that (Total Sales (CY-2)). We then determine the percentage change between these two values.
If there is a decline (negative percent change), we set the current year’s sales target to be 10% higher than the previous year’s sales, indicating a more conservative goal. Conversely, if there was growth (positive percent change), we set the current year target 20% higher to keep the momentum going.
As we dive deeper, combining IF with functions like AND, OR, and NOT we begin to see the true flexibility of these functions in DAX. These logical operators allow us to construct more intricate conditions, tailoring our analysis to very specific scenarios.
The operator functions are used to combine multiple conditions:
AND returns TRUE if all conditions are true
OR returns TRUE if any condition is true
NOT returns TRUE if the condition is false
Let’s craft a measure to determine which employees are eligible for a quarterly bonus. The criterion for eligibility is twofold: the employee must have made at least one sale in the current quarter, and their average sale amount during this period must exceed the overall average sale amount.
To implement this, we first need to calculate the average sales and compare each employee’s average sale against this benchmark. Additionally, we check if the employee has sales recorded in the current quarter to qualify for the bonus.
Employee Bonus Eligibility =
VAR CurrentQuarterStart = DATE(YEAR(TODAY()), QUARTER(TODAY()) * 3 - 2, 1)
VAR CurrentQuarterEnd = EOMONTH(DATE(YEAR(TODAY()), QUARTER(TODAY()) * 3, 1), 0)
VAR OverallAverageSale = CALCULATE(AVERAGE(Sales[Amount]), ALL(Sales))
VAR EmployeeAverageSale = CALCULATE(AVERAGE(Sales[Amount]), FILTER(Sales, Sales[SalesDate] >= CurrentQuarterStart && Sales[SalesDate] = CurrentQuarterStart && Sales[SalesDate] 0
RETURN
IF(
AND(HasSalesCurrentQuarter, EmployeeAverageSale > OverallAverageSale),
"Eligible for Bonus",
"Not Eligible for Bonus"
)
In this measure we define the start and end dates of the current quarter, then we calculate the overall average sale across all data for comparison. We then determine each employee’s average sale amount and check if the employee has made any sales in the current quarter to qualify for evaluation.
If an employee has active sales and their average sale amount during the period is above the overall average, they are deemed “Eligible for Bonus”. Otherwise, they are “Not Eligible for Bonus”.
This example begins to explore how we can use IF in conjunction with AND to streamline business logic into actionable insights. These logical functions provide a robust framework for asking detailed questions about our data and receiving precise answers, allowing us to uncover the insights hidden within the numbers.
Beyond the Basics: Advanced Logical Functions in DAX
As we venture beyond the foundational logical functions we step into a world where DAX’s versatility shines, especially when dealing with complex data models in Power BI. More advanced logical functions such as SWITCH and COALESCE bring a level of clarity and efficiency that is hard to match with just basic IF statements.
SWITCH Function: Simplifying Complex Logic
The SWITCH function is a more powerful version of the IF function and is ideal for scenarios where we need to compare a single expression against multiple potential values and return one of multiple possible result expressions. This function helps us provide clarity by avoiding multiple nested IF statements. Here is its syntax.
The expression parameter is a DAX expression that returns a single scalar value and is evaluated multiple times depending on the context. The value parameter is a constant value that is matched with the results of expression, the result is any scalar expression to be evaluated if the result of expression matches the corresponding value. Finally, the else parameter is an expression to be evaluated if the result of expression does not match any value arguments.
Let’s explore. We have a scenario where we want to apply different discount rates to products based on their categories (Smartphone, Laptop, Tablet). We could achieve this by using the following expression for a new calculated column, which uses nested IFs.
Although this would achieve our goal, the use of nested if statements can make the logic of the calculated column hard to read, understand, and most importantly hard to troubleshoot.
Now, let’s see how we can improve the readability and clarity by implementing SWITCH to replace the nested IF statements.
The expression simplifies the mapping of each Product to its corresponding discount rate and provides a default rate for categories that are not explicitly listed.
COALESCE Function: Handling Blank or Null Values
The COALESCE function offers a straightforward way to deal with BLANK values within our data, returning the first non-blank value in a list of expressions. If all expressions evaluate to BLANK, then a BLANK value is returned. Its syntax is also straightforward.
COALESCE(expression, expression[, expression]...)
Here, expression can be any DAX expression that returns a scalar value. These expressions are evaluated in the order they are passed to the COALESCE function.
When reporting on our sales data, encountering blanks can sometimes communicate the wrong message. Using COALESCE we can address this by providing a more informative value when there are no associated sales.
Product Sales = COALESCE([Total Sales], "No Sales")
With this new measure if our Total Sales measure returns a blank, for example due to filters applied in the report, COALESCE ensures this is communicated with a value of “No Sales”. This approach can be beneficial for maintaining meaningful communication in our reports. It ensures that our viewers understand the lack of sales being reported, rather than interpreting a blank space as missing or erroneous data.
These logical functions enrich our DAX toolkit, enabling more elegant solutions to complex problems. By efficiently managing multiple conditions and safeguarding against potential errors, SWITCH and COALESCE not only optimize our Power BI models but also enhance our ability to extract meaningful insights from our data.
With these functions, our journey into DAX’s logical capabilities becomes even more exciting, revealing the depth and breadth of analysis we can achieve. Let’s continue to unlock the potential within our data, leveraging these tools to craft insightful, dynamic reports.
Logical Comparisons and Conditions: Crafting Complex DAX Logic
Delving deeper into DAX, we encounter scenarios that demand a blend of logical comparisons and conditions. This complexity arises from weaving together multiple criteria to craft intricate logic that precisely targets our analytical goals.
We touched on logical operators briefly in a previous section, the AND, OR, and NOT functions are crucial for building complex logical structures. Let’s continue to dive deeper into these with some more hands-on and practical examples.
Multi-Condition Sales Analysis
We want to identify and count the number Sales transactions that meet specific criteria: sales above a threshold and within a particular region. To achieve this, we create a new measure using the AND operator to count the rows in our sales table that meet our criteria.
High Value Sales in US (Count) =
COUNTROWS(
FILTER(
Sales,
AND(
Sales[Amount] > 5500,
RELATED(Regions[Region]) = "United States"
)
)
)
This measure filters our Sales table to sales that have an amount greater than our threshold of $5,500 and have a sales region of United States.
Excluding Specific Conditions
We need to calculate total year-to-date sales while excluding sales from a particular region or below a certain amount. We can leverage the NOT function to achieve this.
This measure calculates the sum of the sales amount that are not within our Asia sales region and are above $5,500. Using NOT we exclude sales from the Asia region and we us the AND function to also impose the minimum sales amount threshold.
Special Incentive Qualifying Sales
Our goal is to identify sales transactions eligible for a special incentive based on multiple criteria: sales amount, region, employee involvement, and a temporal aspect of the sales data. Here is how we can achieve this.
The OR function is used to include sales transactions that either exceed $7,500 or are made in Europe (RegionID = 2) and the NOT function excludes transaction made by an employee (EmployeeID = 4), who is a manager and exempt from the incentive program. The final condition is that the sale occurred in the current year.
The new measure combines logical tests to filter our sales data, identifying the specific transactions that qualify for a special incentive under detailed conditions.
By leveraging DAX’s logical functions to construct complex conditional logic, we can precisely target specific segments of our data, uncover nuanced insights, and tailor our analysis to meet specific business needs. These examples showcase just the beginning of what is possible when we combine logical functions in creative ways, highlighting DAX’s robustness and flexibly in tackling intricate data challenges.
Wrapping Up: From Logic to Action
Our journey through the world of DAX logical functions underscores their transformative power within our data analysis. By harnessing IF, SWITCH, AND, OR, and more, we’ve seen how data can be sculpted into actionable insights, guiding strategic decisions with precision. To explore other DAX Logical Functions or get more details visit the DAX Function Reference.
Logical reasoning in data analysis is fundamental. It allows us to uncover hidden patterns and respond to business needs effectively, demonstrating that the true value of data lies in its interpretation and application. DAX logical functions are the keys to unlocking this potential, offering clarity and direction in our sea of numbers.
As we continue to delve deeper into DAX and Power BI, let the insights derived from logical functions inspire action and drive decision-making. To explore other functions groups that elevate our data analysis check out the Dive into DAX series, with each post comes the opportunity to enhance your data analytics and Power BI reports.
Explore the intricate landscape of DAX in Power BI, revealing the potential to enhance your data analytics with every post.
Thank you for reading! Stay curious, and until next time, happy learning.
And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment and explore new DAX functions, and challenge yourself with real-world data scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.
Dive into the details of blending design and data with custom Power BI themes.
At the intersection of design and data, crafting Power BI themes emerges as a crucial skill for effective and impactful reports that provide a clear and consistent experience. Through thoughtful design choices in color, font, and layout, we can elevate our report development strategy.
Let’s dive into the details of Power BI theme creation and unlock the potential to make our reports informative, impactful, and remembered. Keep reading to explore the blend of design and data, where every detail in our report is under our control.
Throughout this post we will be creating a Power BI theme file and a Power BI report to test our theme, both the file and report are available at the end of the post. Here is what we will explore.
Have you ever stared at one of your Power BI reports and thought, “This could look so much better”? Well, you are not alone. Power BI themes and templates help us turn bland data visualizations into eye-catching reports that keep everyone engaged.
Themes in Power BI focus on the colors, fonts, and visual styles that give our reports a consistent look. Imagine having a signature style that runs through all your reports – that is what themes can help us do. They ensure that every chart, visual, or table aligns with our brand or a project’s aesthetic, making our report both informational and visually appealing.
No matter your Power BI role or skill level furthering our understanding of Power BI themes can significantly impact the quality of reports we create. So, let’s dive in and explore how we can create our own Power BI custom theme. Ready to transform our reports from meh to magnificent?
The Anatomy of a Power BI Theme
Let’s dive into some details and take a peek under the hood of a Power BI theme. If you have ever opened a JSON and immediately closed, again, you are not alone. But once you get the hang of it, it becomes more and more like reading a recipe of the visual aspects of our Power BI report.
Remember, as complex as the Power BI theme file may seem at its core it is structured text used to define properties like colors, fonts, and visual styles in a way Power BI can understand and apply across our reports.
Key Elements to Customize
Theme Colors: These colors are the heart of our theme. The theme colors determine the colors that represent data in our report visuals. When customizing our theme through Power BI Desktop or setting colors of a visual element we will see Color 1 – Color 8 listed, however the list of theme colors in our theme file can have as many colors as we require for automatically assigning colors in our visualizations.
In the theme color section is also where we find our sentiment and divergent colors as well. Sentiment colors are those used in visuals such as the KPI visual to indicate positive, negative, or neutral results. While the divergent colors are used in conditional formatting to show where a data point falls in a range and we define the colors for the maximum, middle, minimum, and null values.
Structural Colors: While theme colors focus on the data visualizations, structural colors deal with the non-data components of our report, such as the background, label colors, and axis gridline colors. These colors help to enhance the overall aesthetic of our reports.
Structural colors can be found in the Advanced subsection of the Name and Colors tab in the Customize theme dialog box.
We can find all the details on what each color class formats in the table at the link below.
Learn more about: What each structural color formats in our Power BI reports
Text Classes: Next, we can specify the font styles for different types of text within our report including defining the font size, color, and font family for things such as titles, headers, and labels.
Within our Power BI theme there are 4 primary classes out of a total of 12 that need to be set. Each of the four primary classes can be found under the Text section of the Customize theme dialog box. The 4 primary classes are the general class which covers most text within each of our visuals, the title class to format the main title and axis titles, the cards and KPIs class to format the callout values in card and KPIs visuals, and the tab headers class to format the tab headers in the key influencers visual.
The other text classes are secondary classes and derive their properties from the primary class they are associated with. For example, a secondary class may select a lighter shade of the font color, or a percentage larger or smaller font size based on the primary class properties.
For details on what each class formats view the table at the link below.
Visual Styles: To define and fine-tune the appearance of various visuals with detailed and granular control we can add or update the visual styles section of our Power BI theme JSON file.
The Power BI Customize theme dialog box offers a start into setting and modify visual styles. On the Visuals tab we will see options to set background, border, header and tooltip colors. It also provides options to set the colors or our report wallpaper and page background on the Page tab, and set the appearance of the filter pane on the Filter pane tab.
The visuals styles offer us the ability to get granular and ensure every visual matches the aesthetics of our report. However, with this comes a lot of details to work through, we will explore just some of the basics later in this post when customizing the Power BI Theme file.
By focusing on these components, the blueprint for crafting a Power BI theme begins to come together. Helping us create reports that resonate with our brand and elevates user experience by creating a clear and consistent Power BI appearance. As we get more comfortable with the nuances and details of what goes into a Power BI theme, we become better equipped to create a theme that brings our reports to life.
Step-by-Step Guide to Creating Our First Power BI Theme
Creating a custom Power BI theme might initially seem like an unattainable task and we may not even know where to start. The good news is that starting from scratch is not necessary. Let’s make the creation of our theme as smooth as possible by leveraging some handy tools and resources to get us started.
Starting Point: Customize Theme in Power BI Desktop
Starting to create our first Power BI theme does not mean we have to start from scratch. In fact, diving headfirst into a blank JSON file might not be the best way to start. Power BI offers a more user-friendly entry point through the Customize theme dialog box. As we saw in the previous section this user-friendly interface lets us adjust and set many of the core elements of our theme.
The beauty of starting here is not only its simplicity, but also the fact that Power BI allows us to save our adjustments as a JSON file. This file can serve as a great starting point for further customization, giving us a solid foundation to customize and build upon.
First, we will start by selecting a built-in theme that is close to what we want our end result to look like. If none of the built-in themes are close, don’t overlook the resources available right from the Theme dropdown menu in Power BI Desktop. Near the bottom we can find a link to the Theme gallery.
This is also where we find the Customize current theme option to get started crafting our Power BI Theme.
Selecting the Customize current theme will open the Customize theme dialog box where we are able to make adjustments to the current theme, and then we can save the theme as a JSON file for further customizations.
For those looking to tailor their theme further, there are numerous online theme generators that might be helpful. These can range from free basic tools to paid for advanced tools.
Crafting Our Theme
We will be creating a light color theme with the core theme colors ranging from blue to green, similar to the one applied to the report seen in the post below.
From Sketch to Screen: Bringing your Power BI report navigation to life for an enhanced user experience.
Theme Name and Colors
First, from the View ribbon we start by selecting the Theme drop down. From here we will start with the built-in Accessible Tidal theme. Once we select the built-in theme to apply it to the report, we navigate back to the Theme dropdown and select Customize current theme near the bottom.
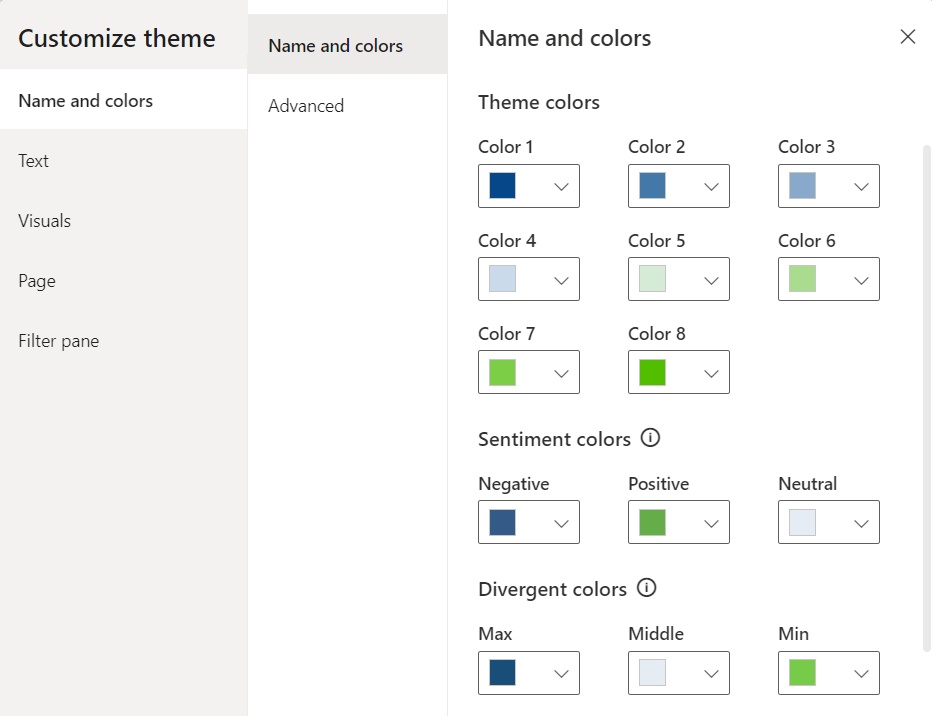
Then we start our customizations on the Name and color tab of the Customize theme dialog box. We set our theme colors, with colors 1-4 ranging from a dark blue to a light blue (#064789, #4478A9, #89A9CA, #CADAEA) and colors 5-8 ranging from a light green to dark green (#D5EBD6, #A9DC8F, #7DCE47, #51BF00). Next, we set the sentiment colors and divergent colors using blue and green as the end points and gray for the midpoint.
Then we hit apply and see how the selected theme colors are reflected in our report. On the left and the bar chart across the top we can see the 8 theme colors. The waterfall chart shows the sentiment colors with green representing an increase and the blue a decrease. Lastly, the divergent colors are utilized in the bottom right bar chart where the bar’s color is based on there percent difference from the average monthly sales values.
After setting the theme, sentiment, and divergent colors we can go back to the Customize theme dialog box and navigate to the Name and colors Advanced section to set our 1st-4th level element colors and our background element colors.
These color elements may not be as straightforward or as easy to identify compared to our core theme colors. Let’s explore some examples of each element.
Here are some of our report elements that are set by the first-, second-, third-, and fourth-level elements color of our customized theme.
And then here are some of our report elements that are set by the background and secondary background colors of our customized theme.
After we have set all of our theme and structural colors, we save our customizations and check in on our Power BI theme JSON file. To save our theme navigate to the Theme dropdown in Power BI and select Save current theme near the bottom. In this file we can see our theme colors listed in the dataColors array, followed by the color elements we set in the advanced section, and then our divergent and sentiment colors.
We can also see a remanent of the built-in theme we selected to start building our custom Power BI theme: tableAccent. We can see this color in our matrix visual, and it is used to set the grid border color.
Let’s use this to complete our first customization of our Power BI theme by editing the theme JSON file and loading the updated theme in Power BI Desktop. To do this, we first update the tableAccent property of the JSON file to the following and save the changes.
"tableAccent": "#51BF00"
Then back in our Power BI report, within the Theme dropdown we select Browse for themes and select our updated Power BI theme JSON file. Power BI will validate our theme file, and once applied we see a dialog box informing us the file was successfully added. And just like that we updated our Power BI custom theme by editing the JSON file.
Now that our theme colors are set, let’s move onto setting our text classes.
Theme Text Classes
In the Customize Theme dialog box we will now shift our focus to the Text tab to set the font styles for various text elements. Within Power BI Desktop we can set the general text, title text, card and KPIs, and tab headers.
Let’s add some more elements to our previous report so we can explore and see more of our theme components in action. Here are some examples of what the different text classes format.
For the theme we are building here is how we will set our text classes:
General – Font family: Segoe UI, Font size: 10, Font color: a dark blue (#053567)
Title – Font family: Segoe UI Semibold, Font size: 12, Font color: a dark blue (#053567)
Cards and KPIs – Font family: Segoe UI, Font size: 26, Font color: our theme color #1 (#064789)
Tab headers – Font family: Segoe UI Semibold: Font size 12, Font color: a dark blue (#053567)
Here is the updated report with our text classes defined in our Power BI theme.
Now we can save the report theme to update the Power BI theme JSON file and check in on the new text classes sections that has been added to it. To save our theme navigate to the Theme dropdown in Power BI and select Save current theme near the bottom.
Let’s continue working through the Customize Theme dialog box and move to the Visuals tab. The Visuals tab allows us to customize the appearance of charts, graphs, and other data visualization components. On this tab we can set the background, border, header, and tooltip property of our visualizations.
Our visual background will be set to a light blue (#F6FAFE).
Then we will move to the next section to turn on and set our visual boarder color to the same dark blue color we used for our text classes (#053567) with a radius of 5.
Next, the header of our visualizations. We will use the same background color as we did in the Background section. For the border and icon color, we will set them to the same color we used in the Border section.
Lastly, we finish up with formatting our Tooltips by setting the label text color and value text color to the same dark blue we have been using for our text elements and the same light blue for the background that we used for the other Visual sections.
Then let’s hit apply and check our report page we are creating to see the different aspects of our theme.
We can also see these updates reflected in the addition of the "visualStyles" property to our Power BI theme file. Before we take a look at the details of our "visualStyles", lets first examine an example of the section.
The visualName and cardName sections are used to specify a visual and card name. Currently, the styleName is always an asterisk ("*").
The propertyName is a formatting option (e.g. color), and the propertyValue is the value used for that formatting option.
For the visualName and cardName we can use an asterisk in quotes ("*") when we want the specified setting to apply to all visuals that have the specific property. When we use "*" for both the visual and card name we can think of this as setting a global setting similar to how our text classes font family and font size is applied across all visuals.
Below is our updated Power BI JSON theme file where we can see the "*" used for the visual and card name, meaning these settings are applied to all our visuals that have the property.
To wrap up our starting point of our customized theme we will move onto the Page and Filter pane tabs of the Customize theme dialog box.
On the page tab we set the wallpaper color to a light blue gray (#F1F4F7) and the page background a slightly lighter shade (#F6FAFE).
On the Filter pane tab, we set the background color to the same color used for the page background, the font and icon color a dark blue similar to our other font and icon colors (#0A2B43), and the same for checkbox and apply color (#053567). The available color background color is set to the same color used for a visual background (#F1F9FF), and the font and icon is set to the same dark blue used in the Filter pane section (#0A2B43). The applied filter card background is set to a gray color (#E5E9ED), and the font and icon color set to the same dark blue (#0A2B43) used in the other filter pane sections.
This resulting theme servers as a great starting point for further customizations and we can edit it directly to add more detailed and granular control of our theme. We will begin to make these granular updates in the next section.
By using the Customize theme dialog box, we streamline the initial steps of theme creation, making it an accessible and less intimidating process. This hands-on approach not only simplifies the creation of our custom theme but also provides a visual and interactive way to see our theme come to life in real-time.
With this foundation set, we are now ready to explore the full potential of our theme by venturing into editing our theme JSON file for more advanced customizations.
Advanced Customization
Once we get the hang of creating, updating, and applying custom themes in Power BI, we might encounter scenarios that require a deeper dive into customizations.
Customize Report Theme JSON File
When we are editing our theme JSON file, we can add the properties we want to add additional formatting to. That is, in our theme file we only have to specify the formatting options that we want to change, any setting that is not specified will revert to the default settings of our theme.
After making our edits we can import our file and Power BI will validate that it can successfully be applied, if there are properties that cannot be validated Power BI will show us a message that the theme file is not valid. The schema used to check our file is updated and available to download here. This report schema can also help us identify properties that we have available to style within our theme file.
To start the journey into advanced customization through editing the JSON file we will focus on our table and matrix visuals, slicers, and the new card visual.
Here is what our default table and matrix visuals look like when our theme is applied.
We will start by updating the formatting of our table visual by adding the tableEx property to our theme file. We will then apply a dark blue fill to our column headers with a light-colored font, set the primary and secondary background colors, and set the totals formatting to match the headers.
Here is the JSON element added to the visualStyles section of our theme file.
Now if we look at background (backcolor) of our columnHeaders we can see that it is hard set to the color value #053567. And depending on our requirements this may work, but it might be preferred (or beneficial) to define this color value in a more dynamic way. The color property can also be defined using expr and reference a theme color (e.g. theme colors 1-8).
Let’s see how this works by updating the backcolor property using a color 25% darker than Color #1 we defined previously in our theme.
The benefit of defining the header background color this way is if we change our primary theme colors our table column header background will update automatically to a darker shade of our Color #1 in our theme. We can do the same with the font color.
Next, we turn our focus to the matrix visual by adding the pivotTable section to our theme file and we will style it similar to our table visual. Here is the pivotTable section added to our theme file.
And then the final results for our table and matrix visual.
Next, we will make some updates to our default slicers. By default, our slicer inherits the same background color and outline as all are other visuals. Since we have the slicers sectioned off in a header we are going to format them slightly differently. We will remove the background and visual boarder for these elements.
Here are our initial slicers for product, region, and year/quarter.
We can add a slicer property to our theme file and then specify we want to set the background transparency to 100% and set the show property of the border to false.
After updating our theme file with these updates and applying them to our report we can see the updated formatting of our slicers.
Now we will shift our focus to the Card (new) visual, specifically we will format the reference label portion of this visualization. By default, the background and divider are gray, we will bring these colors more in line with our theme by setting the background color to a lighter green and the divider to Color #8 of our theme colors. To format this visual we add a cardVisual section to our theme file with the referenceLabel style name specify the backgroundColor and divider properties that we want to format. Here is the cardVisual section added to our theme file.
And then here are the changes to the visualization.
Formatting our table, matrix, slicer, and card (new) visualizations is just the start of the options available to us once we are familiar with customizing our theme file. Piece by piece we can add to this file to continue to fine-tune our theme.
Checkout the final theme file and report at the end to see all the customization made including formatting our visual titles, subtitles, dividers and much more.
Implementing Custom Themes in Power BI Reports
After pouring over the details and meticulously updating our custom theme for our Power BI reports, it is time to bring it to life. Implementing our custom theme helps transform our report from the standard look to something uniquely ours.
How to Apply Our Custom Theme to a Report
First, we must have our report open in Power BI Desktop. Then we can go the View tab, and we will find the Theme dropdown menu. In the Theme menu we scroll to the bottom and select Browse for themes. In the file explorer navigate to our custom theme JSON file and select it. Once selected, Power BI automatically applies the theme to the entire report, giving it an instant new look based on the colors, fonts, and styles we have defined.
Adjusting visuals individually: while our theme sets a global standard for our report, we still have the option to customize individual visuals if it is required. This can be done using the Format pane to make the required adjustments that override the theme setting for that specific element.
Experiment with Colors and Styles: if something does not look quite right, or we find ourselves making the same adjustments to individual visuals over and over, we cannot be afraid to go back to the drawing board. Adjusting our theme file and reapplying it to our report is a quick process that can lead to significant improvements.
Gather Feedback: once our theme is implemented, gather feedback from end-users. They might offer valuable insights into how our theme performs in real-world scenarios and suggest further improvement.
Implementing a custom theme in Power BI improves the aesthetics of our reports while also enhancing the way information is presented and consumed. With our custom theme applied, our reports will not only align with our visual identity but also offer a more engaging and coherent experience for our users.
Creating a Template Report to Test Our Theme
After mastering custom themes in Power BI, taking the next step to create a template report can significantly streamline our workflow. A template report serves as a sandbox for testing our theme and any updates we make.
Having a template report will enable us to see how our theme performs across a variety of visuals and report elements before rolling it out to our actual reports.
How to Create a Template Report: A Step-by-Step Approach
Selecting Visuals and Layouts: We start by creating a new report in Power BI Desktop. In the report include a wide range of visuals that are commonly used. This diversity ensures that our theme is thoroughly tested across different data representations.
Incorporating Various Data Visualization Types for Comprehensive Testing: To truly test our theme, beyond the commonly used visuals, also mix in and experiment with other visuals that Power BI offers. Apply conditional formatting where applicable to see how our theme handles dynamically changing visuals elements.
Tips for Efficient Template Report Design:
Use sample data that reflects the complexity and diversity of real datasets. This ensures that our theme is tested in conditions that closely mimic actual reporting scenarios.
Label our visuals clearly to identify them easily when reviewing how the theme applies to different elements. This can help us spot inconsistencies or areas for improvement in our theme.
Iterate and refine. As we apply our theme to the template report, we might find areas where adjustments are necessary. Use this as an opportunity to refine our theme before deploying it widely.
Creating a template report is an invaluable step in theme development. It offers a controlled environment to experiment with design choices and see firsthand how they translate into actual reports. By taking the time to craft and utilize a template report, we ensure that our custom theme meets our aesthetic expectations while enhancing the readability and effectiveness of our Power BI reports.
Leveraging Power BI Themes and Templates
Let’s build a report to view and test our themes. The first page we add is meant to mimic the spacing and visualization balance of a report page, while also including elements that utilize the theme colors, sentiment colors, and divergent colors.
On this page we can see the main colors of our theme on the Product and Region bar charts, the sentiment colors on the waterfall chart, and the divergent colors on the Totals Sales by MonthYear bar chart on the bottom right. Additionally, we can see the detailed updates we made to the matrix visual and slicers.
The other pages of the report focus on displaying the theme colors and their variations, and specific elements or visualization groups available to us in Power BI. Take a look at each page in the gallery below.
Eager to dive into the details?
The final report and JSON theme created throughout this post can found on my GitHub at the link below.
This dynamic repository is the perfect place to enhance your learning journey.
Wrapping Up
As we begin to learn and understand more about Power BI themes and how to efficiently leverage them, we start to unlock a new level of data visualization and report development.
We have navigated the intricacies of creating a custom theme, from understanding the fundamental components to implementing advanced customization techniques. Along the way, we also discovered the value of a template report in testing and refining our Power BI themes. Having a go to report to test our theme development helps us ensuring they not only meet our aesthetic standards but also enhance the readability and accessibility of our reports.
As we complete this exploration of Power BI themes, it becomes clear that the journey does not end here, in fact it is only just the starting point. The field of data visualization is dynamic, with new trends, tools, and best practices emerging regularly. Meaning, the ongoing refinement of our Power BI themes is not just a static task to mark as complete, it is an opportunity to continuously enhance the effectiveness and impact of our Power BI reports.
Armed with our new understanding of Power BI themes, it is time to go explore more, experiment with updates, and continue to transform our reports into even more powerful tools.
Thank you for reading! Stay curious, and until next time, happy learning.
And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment, explore, and challenge yourself with real-world scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.
In data analytics effectively navigating, understanding, and interpreting our data can be the difference between data-driven insights and being lost in a sea of data. In this post we will focus on a subset of DAX functions that help us explore our data – the Information Functions.
These functions are our key to unlocking deeper insights, ensuring data integrity, and enhancing the interactivity of our reports. Let’s embark on a journey to not only elevate our understanding of Power BI and DAX but also to harness the full potential of our data.
The Role of Information Functions in DAX
Information functions play a crucial role in DAX. They are like the detective of our Power BI data analysis, helping us identify data types, understand relationships, handling errors, and much more. Whether we are checking for blank values, understanding the data type, or handling various data scenarios, information functions are our go-to tools.
Diving deep into information functions goes beyond today’s problems and help prepare for tomorrow’s challenges. Mastering these functions enables us to clean and transform our data efficiently, making our analytics more reliable and our insights more accurate. It empowers us to build robust models that stand the test of time and data volatility.
In our exploration through the world of DAX Information Functions, we will explore how these functions work, why they are important, and how we can use them to unlock the full potential of our data. Ready to dive in?
For those of you eager to start experimenting there is a Power BI report pre-loaded with the same data used in this post ready for you. So don’t just read, follow along and get hands-on with DAX in Power BI. Get a copy of the sample data file here:
This dynamic repository is the perfect place to enhance your learning journey.
The Heartbeat of Our Data: Understanding ISBLANK and ISEMPTY
In data analysis knowing when our data is missing, or blank is key. The ISBLANK and ISEMPTY functions in DAX help us identify missing or incomplete data.
ISBLANK is our go-to tool to identify voids within our data. We can use this function to locate and handle this missing data either to report on it or to manage it, so it does not unintentionally impact our analysis. The syntax is straightforward.
ISBLANK(value)
Here, value is the value or expression we want to check.
Let’s use this function to create a new calculated column to check if our sales amount is blank. This calculated column can then be used to flag and identify these records with missing data, and ensure they are accounted for in our analysis.
MissingSalesAmount = ISBLANK(Sales[Amount])
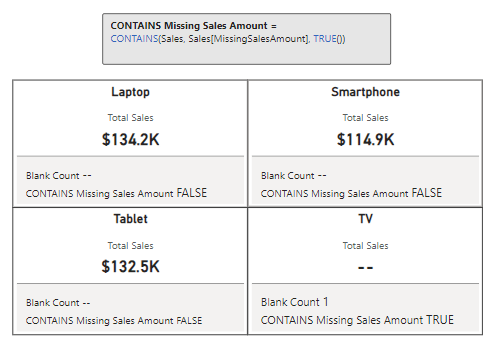
We can now use this calculated column to provide a bit more context to card visuals showing our total sales for each of our products.
In this example we can see the total sales for each product category. However, if we only show the total sales value it could lead our viewers to believe that the TV category has no sales. By adding a count of TV Sales records that have a blank sales amount we can inform our viewers this is not the case and that there is an underlying data issue.
While ISBLANK focuses on the individual values, ISEMPTY takes a step back to consider the table as a whole. We can use this function to check whether the table we pass to this DAX expression contains data. Its syntax is also simple.
ISEMPTY(table_expression)
The table_expression parameter can be a table reference or a DAX expression that returns a table. ISEMPTY will return a value of true if the table has no rows, otherwise it returns false.
Let’s use ISEMPTY in combination with ISBLANK to check if any of our sales records have a missing or blank employee Id. Then we can use this information, to display the count of records (if any) and the total sales value of these records.
In this example we see that Sales with No EmployeeId returns a value of false, indicating that the table resulting from filtering our sales records to sales with a blank employee Id is not empty and contains records. We can then also make use of this function to help display the total sales of these records and a count.
These two functions are the tools to use when investigating our datasets for potentially incomplete data. ISBLANK can help us identify rows that need attention or consideration in our analysis and ISEMPTY helps validate if a subset of data exists in our datasets. To effectively utilize these two functions, it is important to remember their differences. Remember ISBLANK checks if an individual value is missing data, while ISEMPTY examines if a table contains rows.
The Data Type Detectives: ISTEXT, ISNONTEXT, ISLOGICAL and ISNUMBER
In the world of data, not every value is as it seems and that is where this set of helpful DAX expressions come into play. These functions help identify the data types of the data we use within our analysis.
Each function checks the value and returns true or false. We will use a series of values to explore how each of these functions work. To do this we will create a new table which uses each of these functions to check the values: TRUE(), 1.5, “String”, “1.5”, and BLANK(). Here is how we can do it.
An then we can add a table visual to our report to see the results and better understand how each function treats our test values.
The power of these functions lies in their simplicity, the clarity they can bring to our data preparation process, and their ability to be used in combination with other expressions to handle complex data scenarios.
DAX offers a number of other functions that are similar to the ones explored here such as ISEVEN, ISERROR, and ISAFTER. Visit the DAX reference guide for all the details.
A common issue we can run into in our analysis is assuming data types based on a value’s appearance or context, leading to errors in our analysis. Mistakenly performing a numerical operation on a text field that appear numeric can easily throw our results into disarray. Using these functions early in our process to understand our data paves the way for clean, error-free data processing.
The Art of Data Discovery: CONTAINS & CONTAINSSTRING
When diving into our data, pinpointing the information we need can be a daunting task. This is where DAX steps in and provides us CONTAINS and CONTAINSSTRING. These functions help us uncover the specifics hidden within our data.
CONTAINS can help us identify whether a table contains a row that matches our criteria. Its syntax is as follows.
The table parameter can be any DAX expression that returns a table of data, columnName is the name of an existing column, and value is any DAX expression that returns a scalar value that we are searching for in columnName.
CONTAINS will return a value of true if each specified value can be found in the corresponding columnName (i.e. columnName contains value), otherwise it will return false.
In our previous ISBLANK example we created a Blank Count measure to help us identify how many sales records for our product categories are missing sales amounts.
Now, if we are interested in knowing just if there are missing sales amounts, we could update this expression to return true if COUNTROWS returns a value greater than 0, however this is where we can use CONTAINS to create a more effective measure.
CONTAINS can be a helpful tool, however, it is essential to distinguish when it is the best tool for the task versus when an alternative might offer a more streamlined approach. Alternatives to consider include functions such as IN, FILTER, or TREATAS depending on the need.
For example, CONTAINS can be used to establish a virtual relationship between our data model tables, but functions such as TREATAS may provide better efficiency and clarity. For details on this function and its use check out this post for an in-depth dive into DAX Table Manipulation Functions.
Discover how to Reshape, Manipulate, and Transform your data into dynamic insights.
For searches based on textual content, CONTAINSTRING is our go to tool. It specializes in revealing rows where text columns contain specific substrings. The syntax is straightforward.
CONTAINSSTRING(within_text, find_text)
The within_text parameter is the text we want to search for the text passed to the find_text parameter. This function will return a value of true if find_text is found, otherwise it will return false.
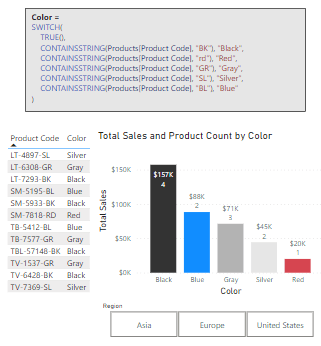
We can use CONTAINSSTRING to dissect our Product Code and enrich our dataset by adding a calculated column containing a user-friendly color value of the product. Here is how.
This new calculated column provides us the color of each product that we can use in a slicer, or we can visualize our totals sales by the product color.
CONSTAINSSTRING is case-insensitive, as shown in the red color statement above. When we require case-sensitivity CONSTAINSSTRINGEXACT provides us this functionality.
CONTAINSSTRING just begins to scratch the surface of the DAX functions available to use for in-depth textual analysis, to continue exploring visit this post that focuses solely on DAX Text Functions.
Stringing Along with DAX: Dive Deep into Text Expressions
By leveraging CONTAINS and CONTAINSTRING – alongside understanding when to employ their alternatives – we are equipped with the tools required for precise data discovery within our data analysis.
Deciphering Data Relationships: ISFILTERED & ISCROSSFILTERED
Understanding the dynamics of data relationships is critical for effective analysis. In the world of DAX, there are two functions we commonly turn to that guide us through the relationship network of our datasets: ISFILTERED and ISCROSSFILTERED. These functions provide insights into how filters are applied within our data model, offering a deeper understanding of the context in which our data operates.
ISFILTERED offers a window into the filtering status of a table or column, allowing us to determine whether a filter has been applied directly to that table or column. This insight is valuable for creating responsive measures that adjust based on user selections or filter context. The syntax is as follows.
ISFILTERED(tableName_or_columnName)
A column or table is filtered directly when a filter is applied to any column of tableName or specifically to columnName.
Let’s create a dynamic measure that leverages ISFILTERED and reacts to user selections. In our data model we have a measure that calculates the product sales percentage of our overall total sales. This measure is defined by the following expression.
Product Percentage of All Sales =
VAR _filterdSales = [Total Sales]
VAR _allSales = CALCULATE([Total Sales], ALL(Products[Product]))
RETURN
DIVIDE(_filterdSales, _allSales, 0)
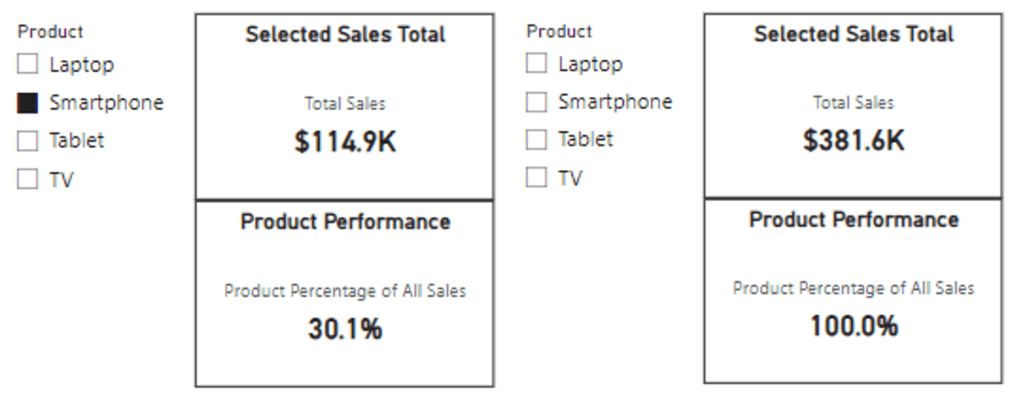
We can see this measure displays the percentage of sales for the selected product. However, when no product is selected it displays 100%, although this is expected and correct, we would rather not display the percentage calculation when there is no product selected in our slicer.
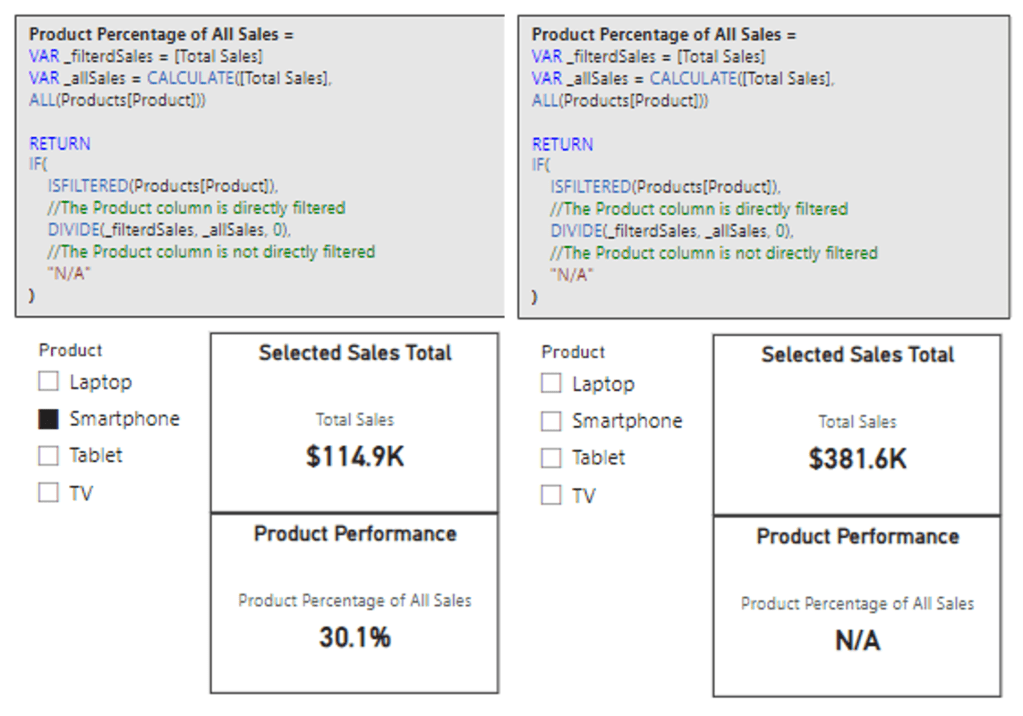
This is a perfect case to leverage ISFILTERED to first check if our Products[Product] column is filtered, and if so, we can display the calculation, and if not, we will display “N/A”. We will update the measure’s definition to the following.
Product Percentage of All Sales =
VAR _filterdSales = [Total Sales]
VAR _allSales = CALCULATE([Total Sales], ALL(Products[Product]))
RETURN
IF(
ISFILTERED(Products[Product]),
//The Product column is directly filtered
DIVIDE(_filterdSales, _allSales, 0),
//The Product column is not directly filtered
"N/A"
)
And here are the updated results, we can now see when no product is selected in the slicer the measure displays “N/A”, and when the user selects a product, the measure displays the calculated percentage.
While ISFILTERED focuses on direct filter application, understanding the impact of cross-filtering, or how filters on one table affect another related table, is just as essential in our analysis. ISCROSSFILTERED goes beyond ISFILTERED and helps us identify if a table or column has been filtered directly or indirectly. Here’s its syntax.
ISCROSSFILTERED(tableName_or_columnName)
ISCROSSFILTERED will return a value of true when the specified table or column is cross-filtered. The table or column is cross-filtered when a filter is applied to columnName, any column of tableName, or any column of a related table.
Let’s explore ISCROSSFILTERED and how it differs from ISFILTERED with a new measure similar to the one we just created. We define the new measure as the following.
Product Percentage of All Sales CROSSFILTER =
VAR _filterdSales = [Total Sales]
VAR _allSales = CALCULATE([Total Sales], ALL(Sales))
RETURN
IF(
ISCROSSFILTERED(Sales),
//Sales table is cross-filtered
DIVIDE(_filterdSales, _allSales, 0),
//The Sales table is not cross-filterd
"N/A"
)
In this measure we utilize ISCROSSFILTERED to check if our Sales table is cross-filtered, and if it is we calculate the proportion of filtered sales to all sales, otherwise the expression returns “N/A”. With this measure we can gain a nuanced view of product performance within the broader sales context.
When our Sales table is only filtered by our Product slicer, we see that the ISFILTERED measure and the ISCROSSFILTERED measure return the same value (below on the left). This is because as before the column Products[Product] is directly filtered by our Product slicer, so the ISFILTERED measure carries out the calculation and returns the percentage.
But also, since our data model has a relationship between our Product and Sales table, the selection of a product in the slicer indirectly filters, or cross-filters, our Sales table leading to our CROSSFILTER measure returning the same value.
We start to see the difference in these functions when we start to incorporate other slicers, such as our region slicer. In the middle image, we can see if no product is selected our Product Performance card display “N/A”, because our Products[Product] column is not being directly filtered.
However, the Sales Performance card that uses our CROSSFILTER measure is dynamically updated to now display the percentage of sales associated with the selected region. Again, this is because our data model has a relationship between our Region and Sales table, so the selection of a region is cross-filtering our sales data.
Lastly, we can see both measures in action when a Product and Region are selected (below on the right).
Using ISFILTERED, we can create reports that dynamically adjust to user interactions, offering tailored insights based on specific filters. ISCROSSFILTERED takes this a step further by allowing us to understand and leverage the nuances of cross-filtering impacts within our data, enabling an even more sophisticated analytical approach.
Applying these two functions within our reports allows us to enhance data model interactivity and depth of analysis. This helps us ensure our reports respond intelligently to user interactions and reflect the complex interdependencies within our data.
Wrapping Up
Compared to other function groups DAX Information Functions may be overlooked, however these functions can hold the key to unlocking insights, providing a deeper understanding of our data’s structure, quality, and context. Effectively leveraging these functions can elevate our data analysis and integrating them with other DAX function categories can lead to the creation of dynamic and insightful solutions.
As we continue to explore the synergies between different DAX functions, we pave the way for innovative solutions that can transform raw data into meaningful stories and actionable insights. For more details on Information Functions and other DAX Functions visit the DAX Reference documentation.
Thank you for reading! Stay curious, and until next time, happy learning.
And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment and explore new DAX functions, and challenge yourself with real-world data scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.
Discover how to Reshape, Manipulate, and Transform your data into dynamic insights.
Exploring DAX: Table Manipulation Functions
Dive into the world of DAX and discover its critical role in transforming raw data into insightful information. With DAX in Power BI, we are equipped with a powerful tool providing advanced data manipulation and analysis features.
Despite its advanced capabilities, DAX remains approachable, particularly its table manipulations functions. These functions are the building blocks of reshaping, merging, and refining data tables, paving the way for insightful analysis and reporting.
Let’s explore DAX table manipulations functions and unlock their potential to enhance our data analysis. Get ready to dive deep into each function to first understand it and then explore practical examples and applications.
For those of you eager to start experimenting there is a Power BI report pre-loaded with the same data used in this post ready for you. So don’t just read, follow along and get hands-on with DAX in Power BI. Get a copy of the sample data file here:
When it comes to enhancing our data tables in Power BI, ADDCOLUMNS is one of our go-to tools. This expression helps us add new columns to an existing table, which can be incredibly handy for including calculated fields or additional information that was not in the original dataset.
Here, <table> is an existing table or any DAX expression that returns a table of data, <name> is the name given to the column and needs be enclosed in double quotes, and finally <expression> is any DAX expression that returns a scalar value that is evaluated for each row of <table>.
Let’s take a look how we can create a comprehensive date table using ADDCOLUMNS. We will start with the basics by creating the table using CALENDARAUTO() and then enrich this table by adding several time-related columns.
In this example, we transform a simple date table into a multifaceted one. Each additional column provides a different perspective of the date, from the year and quarter to the month name and day of the week. This enriched table becomes a versatile tool for time-based analysis and reporting in Power BI.
With ADDCOLUMNS, our data tables go beyond just storing data, they become dynamic tools that actively contribute to our data analysis, making our reports richer and more informative.
Joining Tables with DAX: CROSSJOIN, NATURALINNERJOIN & NATURALLEFTOUTERJOIN
In Power BI, combining different datasets effectively can unlock deeper insights. DAX offers powerful functions like CROSSJOIN, NATURALINNERJOIN, and NATURALLEFTOUTERJOIN to merge tables in various ways, each serving a unique purpose in data modeling.
CROSSJOIN: Creating Cartesian Products
CROSSJOIN is our go-to function when we need to combine every row of one table with every row of another table, creating what is known as a Cartesian product. The syntax is simple.
CROSSJOIN(table, table[, table]…)
Here<table> is any DAX expression that returns a table of data. The columns names from the <table> arguments must all be different in all tables. When we use CROSSJOIN the number of rows in the resulting table will be equal to the product of the number of rows from all <table> arguments, and the total number of columns is the sum of all the number of columns in all tables.
We can use CROSSJOIN to create a new table containing every possible combination of products and regions within our dataset.
This formula will create a new table where each product is paired with every region, providing a comprehensive view for various analysis task such as product-region performance assessments.
When it comes to joining tables based on common columns, NATURALINNERJOIN and NATURALLEFTOUTERJOIN can be helpful. These functions match and merge tables based on column with the same names and data types.
NATURALINNERJOIN creates a new table containing rows that have matching values in both tables, this function performs an inner join of the tables. Here is the syntax.
NATURALINNERJOIN(left_table, right_table)
The <left_table> argument is a table expression defining the table of the left side of the join, and the <right_table> argument defines the table on the right side of the join. The resulting table will include only the rows where the values in the common columns are present in both tables. This table will have the common columns from the left table and other columns from both tables.
For instance, to see products data and sales data for only products that have sales we could create the following table.
NATURALLEFTOUTJOIN, on the other hand, includes all the rows from the first (left) table and the matched rows from the second (right) table. Unmatched rows in the first table will have null values in columns of the second table. This is useful for scenarios where we need to maintain all records from one table while enriching it with data from another. Its syntax is the same as NATURALINNERJOIN.
NATURALLEFTOUTERJOIN(left_table, right_table)
The resulting table will include only rows from the <right_table> where the values in the common columns specified are also present in the <left_table>.
Let’s explore this and how it differs from NATURALINNERJOIN by creating the same table as above but this time using NATURALLEFTOUTERJOIN.
Here we can see the inclusion of our TV line of products, which have no sales. NATURALLEFTOUTERJOIN provides a list of all products, along with the sales data where it is available for each product. While the previous example shows that NATURALINNERJOIN provides only products and sales where the ProductID is matched between these two tables.
Each of these functions serves a distinct purpose: CROSSJOIN for comprehensive combination analysis, NATURALINNERJOIN for intersecting data, and NATURALLEFTOUTERJOIN for extending data with optional matching from another table. Understanding when to use each will significantly enhance our data modeling in Power BI.
GROUPBY: The Art of Segmentation
Segmenting data is a cornerstone of data analysis, and in Power BI, the DAX GROUPBY function is a powerful ally for this task. GROUPBY allows you to group a table by one or more columns and performs calculations on each group. It helps us organize our data into manageable clusters, then glean insights from each cluster. The syntax for GROUPBY is as follows.
Let’s break this down. The <table> argument is any DAX expression that returns a table of data. The <groupBy_columnName> argument is the name of an existing column in <table> (or a related table) by which the data is to be grouped and cannot be an expression. The <name> argument is the name given to a new column that is being added to the list returned by GROUPBY enclosed in double quotes. Lastly, <expression> is the expression to be evaluated for each group and must be a supported aggregation iterator function.
For details on aggregation iterator functions visit this in-depth post.
A guide to transforming data into meaningful metrics: Explore essential aggregation functions.
Let’s get into some details and examples.
The general use of GROUPBY is to create a table with a new column(s) which contain aggregated results. When using GROUPBY for grouping and aggregation we must be familiar with the related CURRENTGROUP function. The CURRENTGROUP function returns the set of rows from the table argument of the GROUPBY function that belongs to the current row of the GROUPBY results, and the function can only be used within the GROUPBY expression. This function has not argument and is only supported as the first argument to a supported aggregation function, for a list of supported functions see the reference document below.
However, we will see this returns an error stating:
Function 'GROUPBY' scalar expression have to be Aggregation functions over CurrentGroup(). The expression of each Aggregation has to be either a constant or directly reference the column in CurrentGroup().
We can correct this and get our expected results but updating our expression to:
Although we can use GROUPBY to create the above summary table, for efficient aggregations over physical tables in our data model such as our Sales table we should conder using the functions SUMMARIZECOLUMNS or SUMMARIZE. We will explore these functions later in this post. The true power of GROUPBY is to perform aggregations over intermediate results from DAX table expressions.
We will leverage this use case by creating a new measure that calculates the total sales amount for each product category, but only for the categories where the average sales amount per transaction exceeds a threshold. Here is how we can use GROUPBY and a virtual table to define the Total Sales by High Performing Categories measure.
Total Sales by High Performing Categories =
VAR ThresholdAverage = 3500
VAR IntermediateTable = GROUPBY(
Sales,
Products[Product],
"Total Sales", SUMX(CURRENTGROUP(), Sales[Amount]),
"Average Sales", AVERAGEX(CURRENTGROUP(), Sales[Amount])
)
VAR FilteredTable = FILTER(
IntermediateTable,
[Average Sales] > ThresholdAverage
)
RETURN
SUMX(FilteredTable, [Total Sales])
In this measure we first define the threshold average as $3,500. Then using GROUPBY we create an intermediate table that groups our sales by product and calculates the total sales and average for each product, this is the same expression we used in the above example. We then create another table by filtering the intermediate table to include only the product groups where the average sales exceed the defined threshold. Then we use SUMX to sum up the total sales from the filtered tabled.
We can see the measure returns a total sales value of $267,000 which from the previous example we can see is the sum of our total sales for our Laptop and Tablet product categories, leaving out the Smartphone category which has an average of $3,379 and is below the threshold. This measure effectively uses GROUPBY to segment and analyze our data in a sophisticated manner, tailoring the calculation to specific business requirements.
Using GROUPBY in measures provides immense flexibility in Power BI, enabling us to perform complex aggregations and calculations that are directly reflected in our report visuals.
SUMMARIZE & SUMMARIZECOLUMNS: Summary Magic
In Power BI, creating summary tables is a common requirement, and DAX offers us two powerful functions for this purpose: SUMMARIZE and SUMMARIZECOLUMNS. These functions are designed to simplify the process of aggregating and summarizing data, making it easier to create our reports and dashboards.
SUMMARIZE: The Classic Aggregator
SUMMARIZE allows us to create a summary table by specifying the columns we want to group by and the aggregations we want to perform. It is particularly useful for creating customized groupings and calculations. Here is its syntax.
Here, <table> can be any DAX expression that returns a table of data, <groupBy_columnName> is optional and is the name of an existing column used to create summary groups, <name> is the name given to a summarized column enclosed in double quotes, and <expression> is any DAX expression that returns a single scalar value.
Let’s see how we can more effectively create our Sales by Product summary table. We will create a Sales by Product SUMMARIZE table using the following:
A key difference to note is the use of SUM and AVERAGE compared to the use of SUMX and AVERAGEX that were required when we used GROUPBY. Unlike GROUPBY the SUMMARIZE function has an implied CALCULATE providing the required context to aggregate our values.
SUMMARIZECOLUMNS: Enhanced Efficiency and Flexibility
SUMMARIZECOLUMNS offers enhanced efficiency and flexibility, especially in handling complex filter contexts. It may be preferred over SUMMARIZE for its performance benefits and ease of use with measures. The syntax is:
The <groupBy_columnName> argument is a column reference to a table within our data model, the <filterTable> is a table expression which is added to the filter context of all columns specified by <groupBy_columnName>, <name> specifies the column name, and the <expression> is any DAX expression that returns a single value.
We are interested in calculating the total and average sales by product and region, but only for the previous year. This is a common scenario in business analysis, where understanding historical performance is key. We can use SUMMARIZECOLUMNS to help us achieve this.
We will create a new Last Year Sales by Product and Region table using the following:
Last Year Sales by Product and Region =
SUMMARIZECOLUMNS(
Regions[Region],
Products[Product],
Filter(Sales, Year(Sales[SalesDate]) = Year(TODAY())-1),
"Total Sales", SUM(Sales[Amount]),
"Average Sales", AVERAGE(Sales[Amount])
)
Here we begin with defining the dimension for group with Regions[Region] and Products[Product], this means our resulting summary will include these two levels of data granularity. The FILTER function is applied to the Sales table to include only sales records from the last year. This is achieved by comparing the year of the SalesDate to the previous year (YEAR(TODAY()) - 1). We then define two new columns in our summary: Total Sales, which sums up the amount for each product-region combination, and Average Sales, which calculates the average sales amount.
This example highlights SUMMARIZECOLUMNS and its strength in handling complex data relationships and filters. By seamlessly integrating time-based filtering and multi-dimensional grouping, it enables the creation of insightful, context-rich summary tables, pivotal for time-sensitive business analysis.
In summary, while SUMMARIZE is great for basic aggregation tasks, SUMMARIZECOLUMNS is the go-to function for more complex scenarios, offing better performance and handling of filter context in Power BI.
ROLLUP: Climbing the Aggregation Ladder
The ROLLUP function in DAX is a robust tool in Power BI for creating layered aggregations, especially useful in multi-level data analysis. It facilitates the generation of subtotals and grand totals within a single query, offering a detailed yet consolidated view of your data. ROLLUP modifies the behavior of the SUMMARIZE function by adding rollup rows to the results on columns defined by the <groupBy_columnName> argument.
Understanding the syntax and functionality of ROLLUP is key to leveraging its full potential. The basic syntax of ROLLUP is as follows:
The <groupBy_columnName> argument is a name of an existing column or ROLLUPGROUP function to be used to create summary groups.
To better understand our resulting summary table when using ROLLUP we can incorporate another helpful function: ISSUBTOTAL. We can use ISSUBTOTAL to create another column within our SUMMARIZE expression that returns true if the row contains a subtotal value for the column passed to ISSUBTOTAL as an argument.
Let’s explore an example. Suppose we want to analyze sales data and see subtotals at different levels: by region, then by product within each region, and finally a grand total across all regions and products. Here is how ROLLUP and ISSUBTOTAL can help.
Sales by Region and Production Rollup =
SUMMARIZE(
Sales,
Regions[Region],
ROLLUP(Products[Product]),
"Total Sales", SUM(Sales[Amount]),
"Product SubTotal", ISSUBTOTAL(Products[Product])
)
This example uses SUMMARIZE and groups our Sales data by Region. Then using ROLLUP it generates subtotals first at the product level within each region, followed by region-level subtotals. Total Sales calculates the sum of sales amounts for each group. Product SubTotals, through ISSUBTOTAL indicates whether a row is a subtotal for a product, enhancing the analysis by clearly marking these subtotal rows.
This approach, using ROLLUP with SUMMARIZE is highly effective for multi-layered data analysis. It allows for an intricate breakdown of data, showcasing how individual segments (in the example, products within regions) cumulatively contribute to broader totals. Such a perspective is critical for in-depth data analysis and informed decision-making.
SELECTCOLUMNS: Handpicking Your Data
In Power BI, tailoring our dataset to include just the right columns is often essential for efficient and focused analysis. This is where the SELECTCOLUMNS function in DAX becomes invaluable. SELECTCOLUMNS allows us to create a new table by selecting specific columns from an existing table. The syntax for SELECTCOLUMNS is straightforward:
The arguments of this function are <table> which is any DAX expression that returns a table, <name> is the name given to the column, and <expression> is any expression that returns a scalar value.
Let’s use SELECTCOLUMNS to create a simplified table from our dataset, focusing on product sales and the corresponding sales date.
Set operations in DAX including UNION, INTERSECT, and EXCEPT are fundamental in Power BI for efficiently managing and manipulating data sets. Each operation serves a unique purpose in data analysis, allowing for combining, intersecting, and differentiating data sets.
UNION: Merging Data Sets
UNION is used to combine two or more tables by appending rows from one table to another. The tables must have the same number of columns, and corresponding columns must have compatible data types. Here is its syntax.
The <table_expression> arguments are any DAX expression that returns a table.
In our data model we have our products table and a new table containing other products, we can use UNION to merge these two product tables.
INTERSECT: Finding Common Elements
INTERSECT returns the common rows between two tables. This function is useful when we need to identify overlapping data. It’s syntax is simple.
INTERSECT(table_expression1, table_expression2)
The <table_expression> arguments are any DAX expression that returns a table. Duplicated rows are retained. The column names in the resulting table will match the column names in <table_expression1>. The table returned by INTERSECT has lineage based on the column in <table_expression1> regardless of the lineage of the columns in the second table.
Let’s use our new All Products table and INTERSECT to examine what products have sales.
EXCEPT takes two tables and returns the rows from the first table that are not found in the second table. This is useful for finding discrepancies or exclusions between datasets.
The syntax for EXCEPT will look familiar.
EXCEPT(table_expression1, table_expression2)
Where <table_expression> can be any DAX expression that returns a table.
Let’s look at the list of ProductIDs that do not have sales, by modifying the above example using EXCEPT.
Understanding and utilizing UNION for merging data, INTERSECT for finding common data, and EXCEPT for identifying unique data helps enhance our data manipulation and analysis capabilities in Power BI.
DISTINCT: Identifying Unique Values
Identifying unique values in a data set is a common requirement, and the DISTINCT function in DAX provides a straightforward solution. DISTINCT is used to return table that contains the distinct values from a specified column or table. This function can help remove duplicate values and obtain a list of unique entries for further analysis.
The syntax for DISTINCT is simple.
DISTINCT(column)
Here, <column> is the column from which distinct values are to be returned, or an expression that returns a column. When we are using DISTINCT it is important to be aware that the results of this function are affected by the current filter context. For example, if we use DISTINCT to create a measure of the distinct products from our sales table, the result of this measure would change whenever our Sales table was filtered by date or region for example.
Using DISTINCT on a Column
When applied to a column, DISTINCT generates a one column table of unique values from the specified column. For example, we want to create a measure that returns the column of employees that have a sale. For this we can use DISTINCT to get a list of the distinct employee Ids from our Sales table and pass the list to the COUNTROWS functions to produce the count. Here is the expression.
Count of Employee with Sales =
COUNTROWS(
DISTINCT(
Sales[EmployeeID]
)
)
Using DISTINCT on a Table
When used on a table, DISTINCT returns a table with unique rows, effectively removing any duplicated rows. We can use this to examine our Sale table to identify if there are any duplicated sales records. We will create two measures, the first to return the count of rows in our Sales table and the second to return the count of rows of our Sales table using DISTINCT.
Our Count of Sales DISTINCT measure produced a count of our Sales table where each row is unique across all columns in the table. With this compared to our count of Sales we can identify our Sales table has a duplicated record.
TREATAS: Bridging Data Tables
A common challenge we may encounter is linking data from different tables that do not have a direct relationship in the data model. TREATAS in DAX is a powerful function designed to address this issue. It applies the values from one table as filters to another unrelated table. This can be especially useful when we are working with complex models where establishing direct relationships may not be feasible or optimal.
The arguments of TREATAS are the <table_expression> which is an expression that results in a table, and <column> which is one or more existing columns, it cannot be an expression. The table returned by TREATAS contains all the rows in <column(s)> that are also in <table_expression>. When using TREATAS the number of columns specified must match the number of columns in <table_expression> and they must be in the same order. TREATAS is best used when a relationship does not exist between the tables, if there are multiple relationships between the tables, we should consider using USERELATIONSHIP to specify what relationship to use.
Previously, using SUMMARIZECOLUMNS we created a summary table of sales for the previous year. We now wish to visualize the total sales of this table utilizing a measure that allows the user to filter the value by a selected region.
Let’s start by adding a table to visualize our Last Year Sales by Product and Region table, a card visual to visualize the default aggregation of the Total Sales field in this table, and a slicer to allow for selection of a region.
When we select a region in our slicer, an issue becomes clear. The table and Total Sales card visual are not filtered. This is because there is no direct relationship between our Regions table and our Last Year Sales by Product and Region table. Here is how we can create a measure using TREATAS to help solve this issue.
Last Year Sales by Region =
CALCULATE(
SUM('Last Year Sales by Product and Region'[Total Sales]),
TREATAS(
VALUES(Regions[Region]),
'Last Year Sales by Product and Region'[Region]
)
)
Adding a new card visual to visualize this measure we can see now that the total sales value is filtered by our Region slicer as expected.
By using TREATAS, we can dynamically filter and aggregate data across tables without the need for a physical relationship in the data model. This function is invaluable for creating flexible, context-specific calculations in Power BI.
Wrapping Up: Harnessing the Full Potential of Table Manipulation in DAX
As we wrap up our exploration of table manipulation functions in DAX, it is clear that these tools offer a wealth of possibilities for transforming and understanding our data. The functions we discussed here and many others found in the DAX Reference Guide each serve unique purposes and can be combined in various ways to unlock deeper insights.
These functions offer flexibility in data manipulation, enabling custom analyses and efficient data modeling. Mastering these functions enhances the power of our reports, making them more insightful and interactive. However, as always, it is important to balance complexity with efficiency to maintain sufficient performance.
Thank you for reading! Stay curious, and until next time, happy learning.
And, remember, as Albert Einstein once said, “Anyone who has never made a mistake has never tried anything new.” So, don’t be afraid of making mistakes, practice makes perfect. Continuously experiment and explore new DAX functions, and challenge yourself with real-world data scenarios.
If this sparked your curiosity, keep that spark alive and check back frequently. Better yet, be sure not to miss a post by subscribing! With each new post comes an opportunity to learn something new.